Le nuove opportunità dell’AI: sfruttare GPT 3.5 per la deoffuscazione del codice
.NET deoffuscatore GPT
L’idea di usare un Large Language Model (LLM) per deoffuscare del codice non è nuova. Architetture come GPT di OpenAI (ChatGPT è solo una famosa applicazione di GPT) hanno dimostrato di possedere capacità emergenti in grado di manipolare il linguaggio naturale e di ragionare su frammenti di codice.
Se un LLM può generare e maneggiare del testo arbitrario in modo complesso, forse può fare lo stesso, supposto sia sufficientemente addestrato, per un linguaggio di programmazione di basso livello.
Sul piano tecnico, uno dei compiti più tediosi nel campo della cibersecurity è la deoffuscazione del codice.
Deoffuscare bytecode CIL con GPT 3.5
Abbiamo provato ad usare GPT 3.5 di OpenAI per la deoffuscazione del bytecode Common Intermediate Language (CIL) usato dalle applicationi .NET. Come offuscatore è stato scelto ConfuserEx. I risultati non sono stati ottimi, ma sono stati comunque incoraggianti. Anche se l’obiettivo di avere una IA in grado di deoffuscare codice in modo affidabile non è ancora stato raggiunto, è sicuramente utile sperimentare a riguardo.
E’ comunque ipotizzabile che un LLM appositamente addestrato per la manipolazione di codice (di alto e basso livello) e successivamente allineato su offuscatori specifici possa generare risultati migliori.
OpenAI permette di effettuare operazioni di fine-tuning del suo modello GPT. Questa procedura permette di prendere un modello già addestrato e crearne uno nuovo addestrato su una serie di esempi di dimensioni ridotte. In questo modo è possibile riusare il lavoro fatto per addestrare il modello iniziale per creare un modello adatto a specifiche esigenze.
Alla fine dell’operazione di fine-tuning, GPT 3.5 è riuscito a deoffuscare correttamente:
- una sequenza lineare di istruzioni;
- una sequenza iterativa (un ciclo
for); - una selezione (uno statement
if); - a riproporre parte di una selezione dentro un’iterazione (
ifdentro unfor).
Dove GPT ha generato codice CIL correttamente deoffuscato, lo ha fatto generando frammenti semanticamente equivalenti al codice CIL originale, ma non strutturalmente identici. Ad esempio invertendo correttamente la disposizione dei rami di un if, dimostrando capacità di manipolazione del codice.
Il training set usato consisteva in 211 campioni, un numero limitato volto solo a fungere da prototipo.
Deep Learning nella cibersicurezza
Le tecniche di Deep Learning (DL) non sono nuove di questo decennio, ma – essendo molto onerose in termini di risorse – è stata la crescente disponibilità di potenza computazionale a basso costo a farle fiorire. Kaspersky, ad esempio, usa un architettura Encoder per creare una rappresentazione compatta delle feature di un malware in modo da avere un modello che generalizzi bene anche in presenza di famiglie malware con un singolo sample (tipici di attacchi di altissimo profilo).
Un’area in cui i metodi DL tornano utili nel campo della cibersicurezza, in particolare dell’analisi malware, è la manipolazione di codice. Due applicazioni su tutte sono la decompilazione e la deoffuscazione di codice di basso livello. Rispetto al problema della classificazione delle minacce questi due problemi sono enormemente più complessi e richiedono necessariamente tecniche DL se affrontanti con il Machine Learning (ML). L’architettura usata è una sequence-to-sequence e per questo tipo di reti i transformer si sono dimostrati più espressivi degli approcci rNN.
Premesso che una rete sequence-to-sequence basata su transformer già addestrata è GPT di OpenAI, la stessa si è già dimostrata capace di notevoli abilità emergenti come la manipolazione e la generazione di codice ed è già ampiamente usata ad esempio in sistemi Retrieval Augmented Generation per l’interrogazione su contesti specifici selezionati dall’utente.
Risulta quindi utile fare un tentativo di deoffuscazione di codice CIL con questa rete. Abbiamo scelto GPT 3.5 e non GPT 4 per ragioni economiche, per le stesse ragioni il training set usato è di numerosità limitata.
L’esperimento che segue deve quindi intendersi come un incoraggiamento a sperimentare in questa direzione, poichè le risorse a disposizione non ci permettono di esplorare completamente le potenzialità di GPT o modelli simili.
GPT per la deoffuscazione di codice CIL
Abbiamo deciso di deoffuscare codice CIL solo relativamente alla Control Flow Obfuscation (CFO), ovvero l’offuscazione che riscrive la sequenza originale di istruzioni.
Il codice CIL è molto più semplice da rappresentare e da deoffuscare del codice macchina, perchè la macchina astratta che implementa il runtime delle applicazioni .NET è più ad alto livello e semplice di una CPU x86 o ARM. Limitarci all’offuscazione CFO ci permette di considerare solo il codice presente in un dato metodo, senza dover fornire al modello altri metodi o campi come avviene tipicamente con l’offuscazione delle stringhe o delle chiamate.
In questo modo è possibile rimanere entro i limiti di lunghezza dell’input del modello stesso.
- Abbiamo implementato una trentina di esercizi da scuole superiori scritti in C#;
- Questo codice, insieme al codice stesso di ConfuserEx, è stato poi offuscato permettendoci di avere un insieme di coppie (codice originale, codice offuscato) con cui fare fine-tuning di GPT 3.5;
- Infine abbiamo valutato le sue capacità di deoffuscazione con semplici esempi.
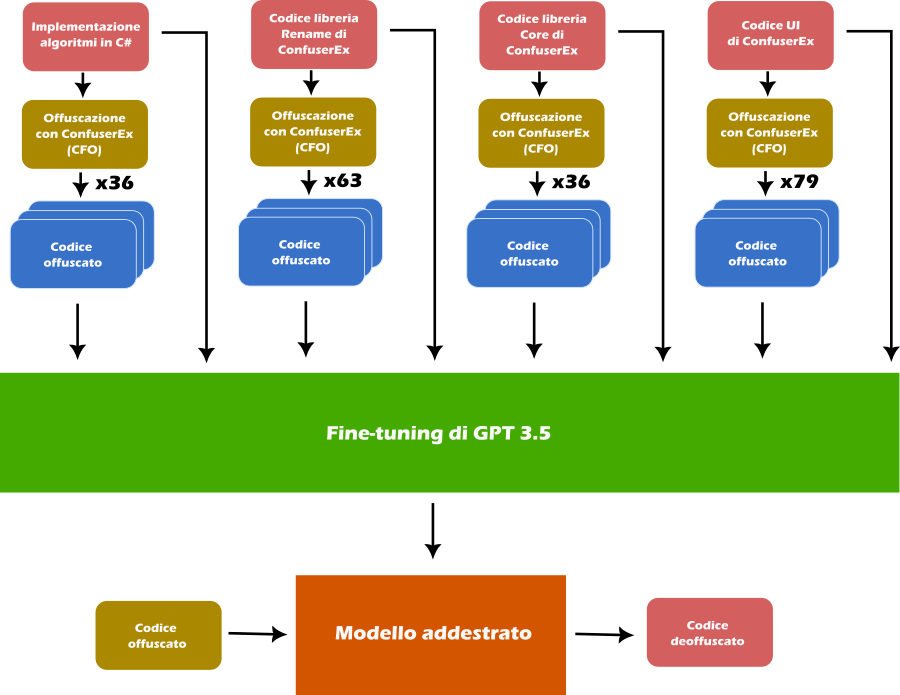
Recupero dei dati
Per ottenere coppie di codice CIL ed il loro equivalente offuscato abbiamo usato il codice stesso di ConfuserEx, prendendo i metodi delle classi nei namespace che ci sembravano più eterogeneei. E’ importante sottolineare che la scelta dei metodi da usare come esempi di training ha grande impatto sull’efficacia del modello. In C# per esempio la scrittura idiomatica di molti cicli non usa costrutti for, ma chiamate a metodi d’estensione (si pensi a LINQ); in ragione di ciò abbiamo poi aggiunto una trentina di metodi che implementano semplici algoritmi iterativi.
Gli assembly scelti sono stati offuscati con ConfuserEx, tenendo attivo solo il plugin per la CFO. Il seguente file di configurazione ConfuserEx può essere usato come template:
<project outputDir="{output_path}" baseDir="{path_to_parent_folder}" xmlns="http://confuser.codeplex.com">
<rule preset="none" pattern="true">
<protection id="ctrl flow" />
</rule>
<module path="{filename_exe}" />
</project>ConfuserEx necessita del percorso della solution (ovvero un insieme di progetti) del programma da offuscare, questo è necessario per poter rifirmare l’assembly offuscato generato in output. In questo contesto non ci serve avere un’assembly firmato, ci interessa solo offuscare il codice. Inoltre i nostri assembly sono già compilati e senza il relativo codice sorgente o progetto. Possiamo usare direttamente la cartella genitore dell’assembly come baseDir, ConfuserEx salterà automaticamente il passo di firma.
Per offuscare un’assembly (o più di uno se specificati nella configurazione) basta passare il percorso del file di configurazione a ConfuserEx (il parametro da riga di comando -n evita una pausa finale):
> Confuser.CLI.exe -n <path_to_config>A questo punto abbiamo gli assembly originali e la loro versione offuscata. Dopo averli spostati in opportune cartelle, possiamo usare dnlib per enumerare i metodi delle classi in un dato namespace e generare una sequenza di sample. Ogni sample sarà caratterizzato da:
- Un nome. Per aiutarci nel debug e nel testing del modello. Questo è il nome del metodo;
- Il listato disassembly del codice offuscato;
- Il listato disassembly del codice originale;
- Un parametro booleano che indica se il metodo è stato offuscato. Questo parametro non è, al momento più usato, ma potrebbe tornare utile nel caso sia necessario inserire esempi negativi, ovvero sample in cui il codice non è offuscato. Questo dovrebbe aiutare GPT a produrre codice CIL valido. Tuttavia, dopo qualche test ci siamo resi conto che GPT è già in grado di produrre codice CIL valido e non abbiamo più usato questo parametro.
Il seguente programma C#, genera gli esempi di training a partire da un insieme di coppie di nomi di assembly e namespace:
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using dnlib.DotNet;
namespace ConsoleApplication6
{
internal class Program
{
private struct Sample
{
public readonly string Name;
public readonly string ObfuscatedIl;
public readonly string DeobfuscatedIl;
public readonly bool IsObfuscated;
public Sample(string name, string obfuscatedIl, string deobfuscatedIl, bool isObfuscated)
{
Name = name;
ObfuscatedIl = obfuscatedIl;
DeobfuscatedIl = deobfuscatedIl;
IsObfuscated = isObfuscated;
}
}
private static string GetIl(MethodDef method) => string.Join("\n", from m in method.Body.Instructions select m.ToString());
private static IEnumerable<MethodDef> GetMethods(string path, string @namespace)
{
var modCtx = ModuleDef.CreateModuleContext();
var module = ModuleDefMD.Load(path, modCtx);
return from t in module.Types
from m in t.Methods
orderby t.FullName
where t.Namespace == @namespace
select m;
}
private static string ToJson(bool b) => $"{b}".ToLower();
private static string ToJson(string s) => $"\"{s.Replace("\\", "\\\\").Replace("\"", "\\\"").Replace("\r", "\\r").Replace("\n", "\\n").Replace("\t", "\\t")}\"";
private static string ToJson(Sample s) => $"{{\"name\": {ToJson(s.Name)}, \"obf_il\": {ToJson(s.ObfuscatedIl)}, \"deobf_il\": {ToJson(s.DeobfuscatedIl)}, \"is_obf\": {ToJson(s.IsObfuscated)} }}";
private static string ToJson(IEnumerable<Sample> l) => $"[{String.Join(", ", from x in l select ToJson(x))}]";
private static IEnumerable<Sample> GetSamples(string deobfPath, string obfPath, string @namespace) =>
from om in GetMethods(obfPath, @namespace)
join dm in GetMethods(deobfPath, @namespace) on om.FullName equals dm.FullName
where !om.IsNative && om.HasBody
select new Sample(om.Name, GetIl(om), GetIl(dm), true);
public static void Main(string[] args)
{
var obfPathBase = @"C:\users\labbe\desktop\Confused\";
var deobfPathBase = @"C:\users\labbe\desktop\Original\";
var sources = new Dictionary<string, string>(){
{"Confuser.Renamer.dll", "Confuser.Renamer.Analyzers" },
{"Confuser.Core.dll", "Confuser.Core.Helpers" },
{"ConfuserEx.exe", "ConfuserEx" },
{"ConsoleApplication7.exe", "ConsoleApplication7" },
};
var samples = from kv in sources
from s in GetSamples(deobfPathBase + kv.Key, obfPathBase + kv.Key, kv.Value)
select s;
File.WriteAllText(@"C:\users\labbe\desktop\gpt\dataset.json", ToJson(samples));
}
}
}Il risultato finale è un file JSON consistente in una lista di oggetti Sample la cui struttura è stata descritta sopra.
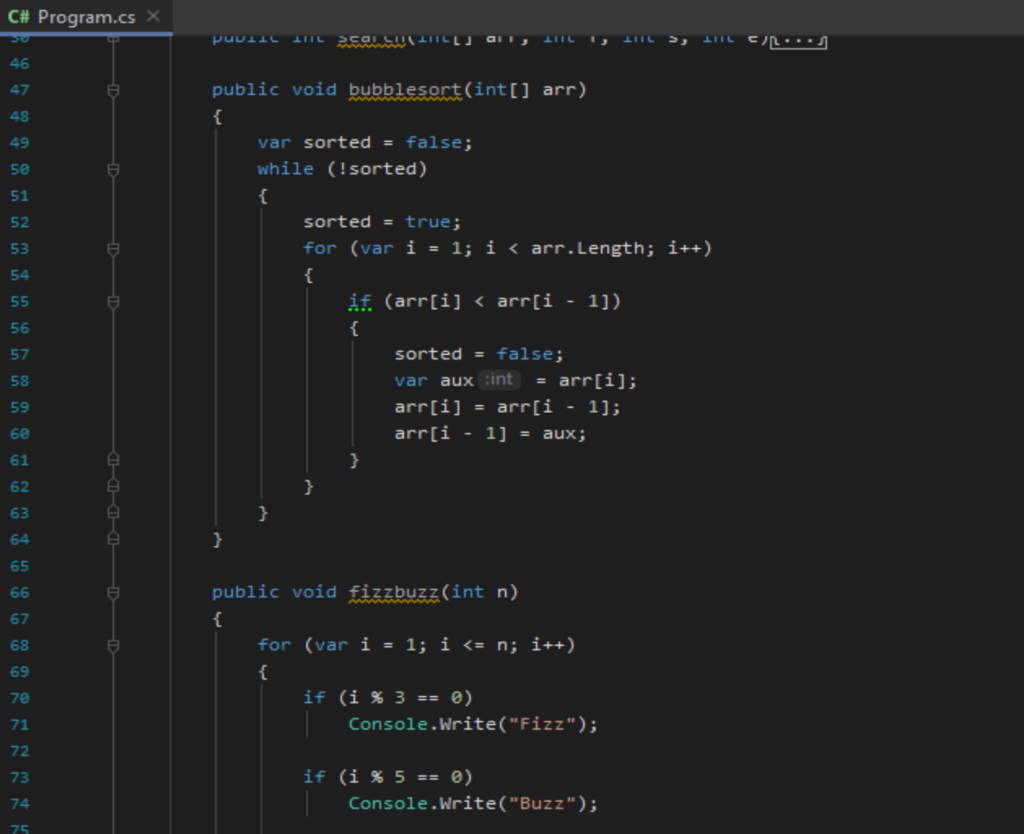
Preparazione dei dati
Il codice CIL estratto con dnlib non usa etichette per i salti, ma offset nel bytecode; inoltre, ogni istruzione è prefissata con il suo offset. Ad esempio si ha:
IL_0000: brtrue IL_0020Queste informazioni sono molto complesse da far generare ad un modello, perchè devono catturare intrinsecamente la dimensione di ogni istruzione CIL e dei suoi operandi. E’ meglio rimuovere gli offset davanti ad ogni istruzione ed usare etichette numerate (es: label1, label2, …) come destinazione dei salti.
Inoltre è bene dividere i dati nel dataset in un training set ed un validation set, abbiamo usato il 10% dei dati come validation set.
Infine, per il fine-tuning di un modello GPT, OpenAI si aspetta una serie di file JSON concatenati tramite newline in un file JSONL e con la seguente forma:
{
"messages": [
{"role": "system", "content": "<optional system prompt>"},
{"role": "user", "content": "<obufscated_il>"},
{"role": "assistant", "content": "<deobfuscated_il>"}
]
}Il seguente script python legge il dataset JSON passato da linea di comando e genera due file <nome-json>.training.jsonl e <nome-json>.validation.jsonl nel formato indicato sopra. Il codice CIL viene trasformato come suggerito precedentemente. Questi file possono poi essere direttamente usati per la creazione del job di fine-tuning.
import json
import random
import re
import sys
import pathlib
filename = sys.argv[1]
basename = pathlib.Path(filename).stem
re_labels = re.compile("IL_[A-F0-9]{4}")
samples = json.load(open(filename))
def prepare_il(il):
#Make a list of ("IL_xxxx", <instructio>) pairs
pairs = [l.split(": ", 1) for l in il.split("\n") if ": " in l ]
#Extract the first column, we'll use this to double check that an IL_xxxx string in <instruction> is actually a label
targets = set(map(lambda x: x[0], pairs))
#Extract all the used labels
used_labels = sorted([m for _, i in pairs for m in re_labels.findall(i) if m in targets], key=lambda x: int(x.replace("IL_", ""), 16))
#Give them a number (this also removes duplicates)
labels = {n : f"label{i+1}" for i,n in enumerate(used_labels)}
#Replace IL_xxxx with label names and add label names before and instruction if its offset matches a label
new_il = "\n".join(("\n" + labels[o] + ":\n" if o in labels else "") + re_labels.sub(lambda m: labels[m.group(0)], i) for o,i in pairs)
return new_il
#Turn one sample in our format into a sample in OpenAI format
def prepare_sample(s):
return {
"messages": [
{"role": "system", "content": "Given the following obfuscated list of .NET IL instructions, deobfuscate it. Write only the deobfuscated list of instructions."},
{"role": "user", "content": prepare_il(s["obf_il"])},
{"role": "assistant", "content": prepare_il(s["deobf_il"])}
]
}
def prepare_sets(samples, mapper, val_perc=10):
#Make the samples
all_samples = list(map(lambda x: json.dumps(mapper(x)), samples))
#Shuffle for uniform distribution
random.shuffle(all_samples)
#How many to keep for validation
val_n = len(all_samples) * val_perc // 100
return all_samples[val_n:], all_samples[:val_n]
def save_jsonl(name, sample_set):
with open(name, "w") as f:
f.write("\n".join(sample_set))
#Make the two sets
trainingset_il, validationset_il = prepare_sets(samples, lambda s: prepare_sample(s))
#Save them
save_jsonl(f"{basename}.training.jsonl", trainingset_il)
save_jsonl(f"{basename}.validation.jsonl", validationset_il)
#Counts
print(f"""Total sample:\t{len(samples)}
Training samples:\t{len(trainingset_il)}
Validation samples:\t{len(validationset_il)}
""")OpenAI mette a disposizione un tutorial su come verificare la correttezza e approssimare il numero di token di un file JSONL per il training.
Fine-tuning
Per il fine-tuning è necessario acquistare un credito per l’uso delle API OpenAI. Acquistato il credito è necessario caricare i file di training e validation e poi creare un job di fine-tuning.
Considerando che abbiamo circa 200 esempi, abbiamo deciso di usare 15 epoche per il training. Il seguente script python crea il job di fine-tuning e mostra periodicamente l’andamento (in formato JSON come ritornato dalle API OpenAI):
import openai
import sys
import time
if len(sys.argv) == 3:
training = openai.File.create(file=open(sys.argv[1]), purpose='fine-tune')
print(f"Training file id: {training['id']}")
validation = openai.File.create(file=open(sys.argv[2]), purpose='fine-tune')
print(f"Validation file id: {validation['id']}")
ftjob = openai.FineTuningJob.create(training_file=training["id"], validation_file=validation["id"], model="gpt-3.5-turbo", hyperparameters={"n_epochs": 15})
else:
ftjob = openai.FineTuningJob.retrieve(sys.argv[1])
print(f"Fine-tuning job id: {ftjob['id']}")
print(ftjob)
print(openai.FineTuningJob.list_events(id=ftjob['id'], limit=10))
while True:
time.sleep(60)
print(openai.FineTuningJob.retrieve(ftjob['id']))
print(openai.FineTuningJob.list_events(id=ftjob['id'], limit=10))Se eseguito passando i nomi del file di training e del file di validation lo script crea un nuovo job di fine-tuning. Se eseguito passando solo il nome di un job di fine-tuning lo script mostra gli ultimi eventi di questo. Dopo l’addestramento il modello è pronto per le interrogazioni.
Verifica del modello
Per la verifica delle capacità del modello appena addestrato abbiamo usato quattro esempi molto semplici (nessuno dei quali era nel dataset ovviamente). Abbiamo volutamente tenuto gli esempi semplici perchè non è ragionevole pensare che il fine-tuning, con 200 esempi, di un LLM general purpose possa portare alla deoffuscazione di codice complesso.
Il fatto che GPT sia in grado di ricreare la sequenza originale di istruzioni per alcuni di questi esempi va inteso come punto di partenza per sviluppi successivi e non come obiettivo finale.
I 4 esempi di seugito riportati riguardano:
- una sequenza lineare di istruzioni;
- una sequenza iterativa (un ciclo
for); - una selezione (uno statement
if); - a riproporre parte di una selezione dentro un’iterazione (
ifdentro unfor).
1. Sequenza lineare
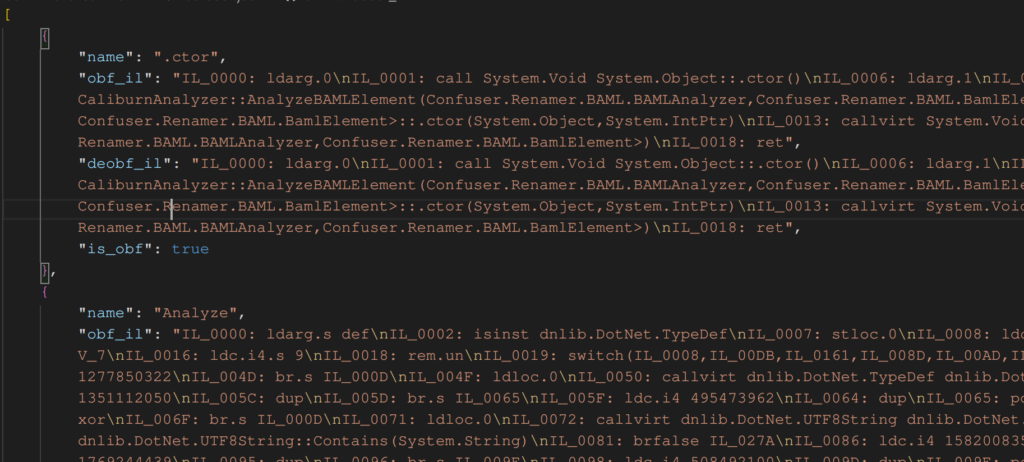
In questo esempio quattro chiamate a Console.WriteLine sono eseguite in successione.
Console.WriteLine("1");
Console.WriteLine("2");
Console.WriteLine("3");
Console.WriteLine("4");
Passando al modello il codice CIL offuscato (colonna di mezzo nell’immagine sopra), si ottiene il seguente codice CIL che corrisponde all’originale:
nop
ldstr "1"
call System.Void System.Console::WriteLine(System.String)
nop
ldstr "2"
call System.Void System.Console::WriteLine(System.String)
ldstr "3"
call System.Void System.Console::WriteLine(System.String)
nop
ldstr "4"
call System.Void System.Console::WriteLine(System.String)
nop
ret2. Sequenza iterativa
In questo esempio un semplice for viene usato per stampare i numeri da 0 a 9.
for (var i = 0; i < 10; i++)
Console.WriteLine($"{i}");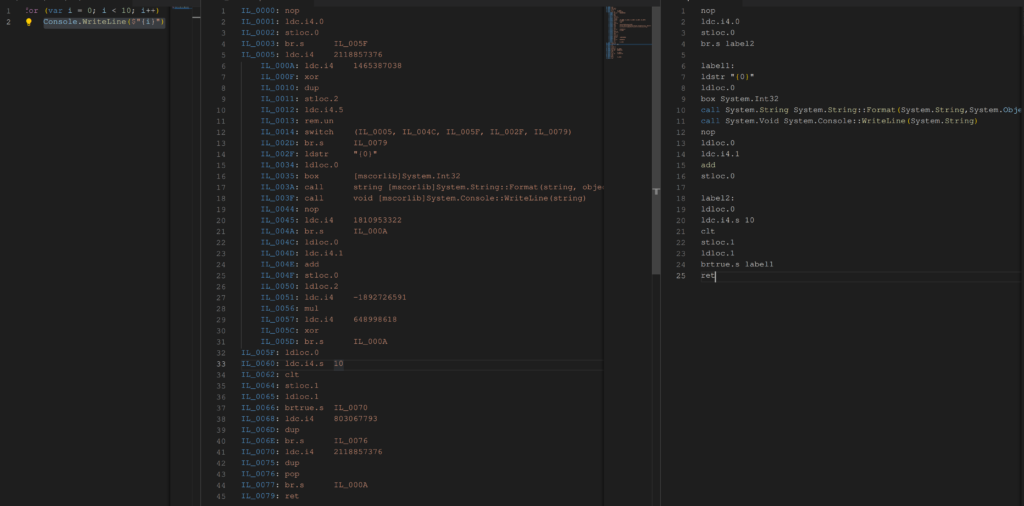
Passando al modello il codice CIL offuscato (colonna di mezzo nell’immagine sopra), si ottiene il seguente codice CIL che corrisponde all’originale:
nop
ldc.i4.0
stloc.0
br.s label2
label1:
ldstr "{0}"
ldloc.0
box System.Int32
call System.String System.String::Format(System.String,System.Object)
call System.Void System.Console::WriteLine(System.String)
ldloc.0
ldc.i4.1
add
stloc.0
label2:
ldloc.0
ldc.i4.s 10
clt
brtrue.s label1
ret3. Selezione
In questo esempio viene usato un semplice if per verificare la presenza di argomenti da linea di comando.
if (args.Length < 2)
Console.WriteLine("Usage: xxxx");
else
Console.WriteLine($"Hello {args[1]}!");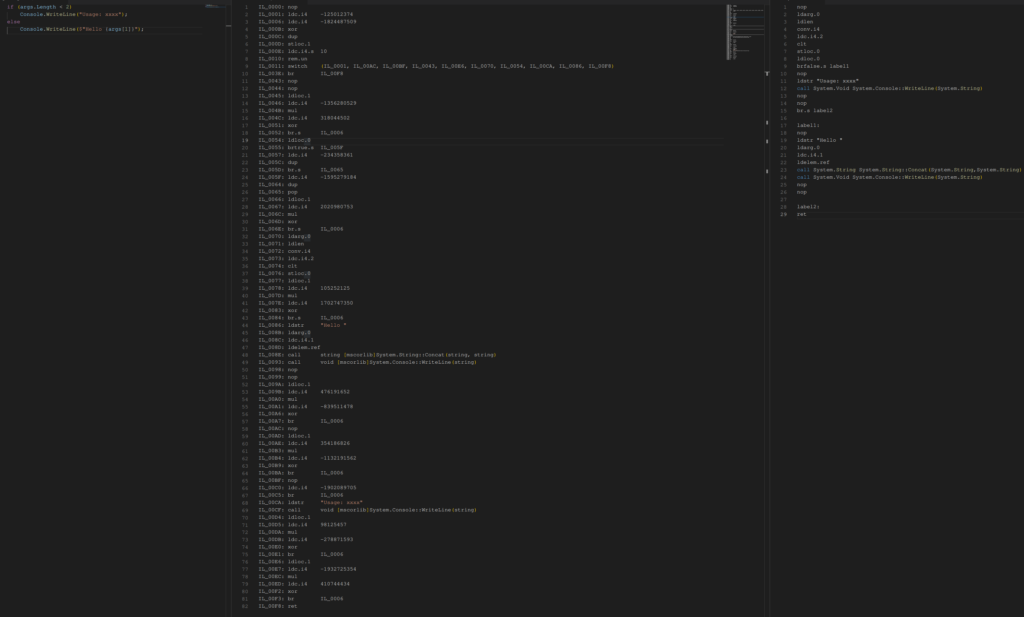
Passandoal modello il codice CIL offuscato (colonna di mezzo nell’immagine sopra), si ottiene il seguente codice CIL che corrisponde semanticamente all’originale ma che è strutturalmente diverso. In particolare GPT ha invertito la disposizione dei due rami dell’if ma ha mantenuto invariata la semantica:
nop
ldarg.0
ldlen
conv.i4
ldc.i4.2
clt
stloc.0
ldloc.0
brtrue.s label1
ldstr "Hello "
ldarg.0
ldc.i4.1
ldelem.ref
call System.String System.String::Concat(System.String,System.String)
call System.Void System.Console::WriteLine(System.String)
nop
nop
br.s label7
label1:
ldstr "Usage: xxxx"
call System.Void System.Console::WriteLine(System.String)
nop
nop
label7:
ret4. Selezione dentro un’iterazione
Tramite un semplice ciclo for ed un if vengono mostrati i numeri da 0 a 9 in cui i numeri dispari sono preceduti da un segno meno.
for (var i = 0; i < 10; i++)
if (i % 2 == 0)
Console.WriteLine($"{i}");
else
Console.WriteLine($"{-i}");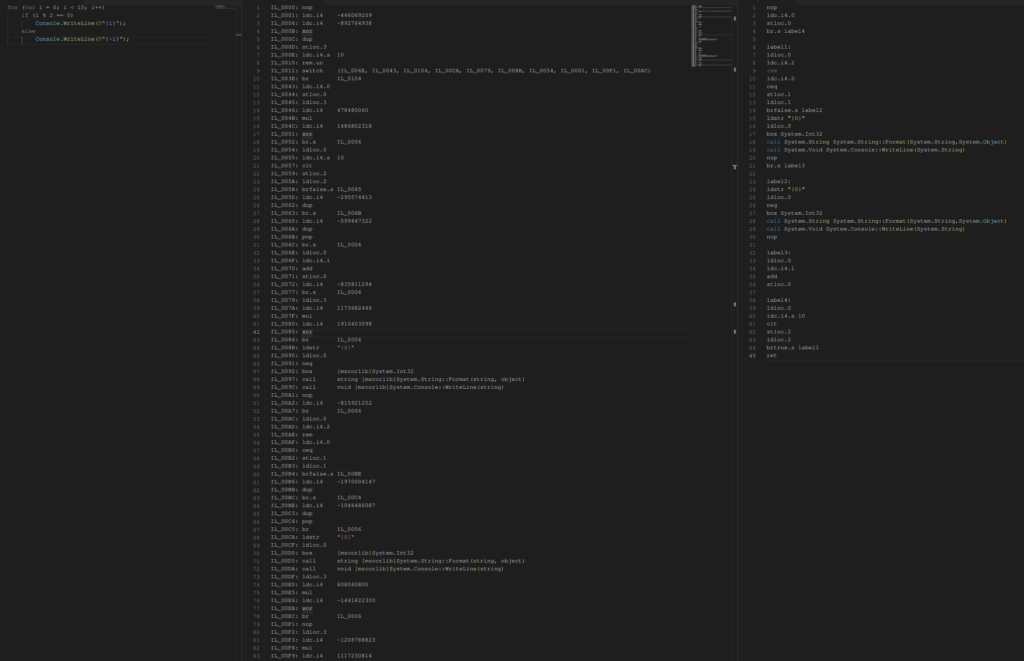
Fornendo al modello il codice CIL offuscato viene generato codice CIL valido, ma non corrispondente all’originale:
nop
ldc.i4.0
stloc.0
br.s label2
label1:
nop
ldstr "{0}"
ldloc.0
box System.Int32
call System.String System.String::Format(System.String,System.Object)
call System.Void System.Console::WriteLine(System.String)
nop
ldstr "{0}"
ldloc.0
neg
box System.Int32
call System.String System.String::Format(System.String,System.Object)
call System.Void System.Console::WriteLine(System.String)
nop
ldloc.0
ldc.i4.1
add
stloc.0
label2:
ldloc.0
ldc.i4.s 10
clt
stloc.2
ldloc.2
brtrue.s label1
retQuesto codice CIL corrisponde al seguente codice C#, che differisce dall’originale per l’assenza della selezione:
for (var i = 0; i < 10; i++) {
Console.WriteLine($"{i}");
Console.WriteLine($"{-i}");
}Riassunto dei risultati
| Test | Deoffuscato correttamente |
| Sequenza lineare | Sì |
| Selezione | Sì (codice con layout diverso) |
| Iterazione | Sì |
| Iterazione con selezione | No |
Conclusioni
Usare l’IA per ricostruire il codice originale dal codice deoffuscato è senz’altro un ramo di ricerca da esplorare. Questo esperimento con GPT 3.5 ha mostrato risultati incoraggianti, anche se lontani dall’essere utili in applicazioni pratiche.
In questo ambito è necessaria una maggiore ricerca per deliniare i limiti e le potenzialità dell’uso di LLM per deoffuscare codice e per comprendere se un LLM sia il modello più idoneo al compito. La deoffuscazione richiede spesso di simulare l’esecuzione di istruzioni e, mentre un LLM può essere abbastanza espressivo da simulare alcune operazioni (incluse chiamate a funzioni esterne scelte dall’utente), un modello in grado di riconoscere cosa simulare e capace poi ripiegare su un simulatore classico, potrebbe avere prestazioni migliori.
Sforzi ancora maggiori sono necessari per “attaccare” tipi di offuscazione diversi dalla CFO, che richiedono in primo luogo di rappresentare l’intero programma in modo utile per essere fruibile dal modello.
Tuttavia, questo semplice esperimento può risultare utile per esplorare le reali capacità di GPT e di modelli simili in ricerche future, o per applicazioni di deoffuscazione di codice in contesti più semplici.
Approfondendo la ricerca è quindi possibile sperare che l’IA possa velocizzare ed automatizzare la comprensione del codice malware, permettendo agli attori coinvolti una migliore e più rapida difesa da questa tipologia di minaccia.