Uno sguardo ai server della Pubblica Amministrazione attraverso i dati di Shodan
CVE shodan vulnerabilità
Shodan è un motore di ricerca che raccoglie le informazioni dei dispositivi, inclusi server, connessi ad internet.
Rispetto ad un motore di ricerca ordinaria, che indicizza il contenuto delle pagine web, Shodan cataloga i metadati dei dispositivi, come i banner dei servizi esposti, le porte aperte, le versioni dei software rilevate e altro.
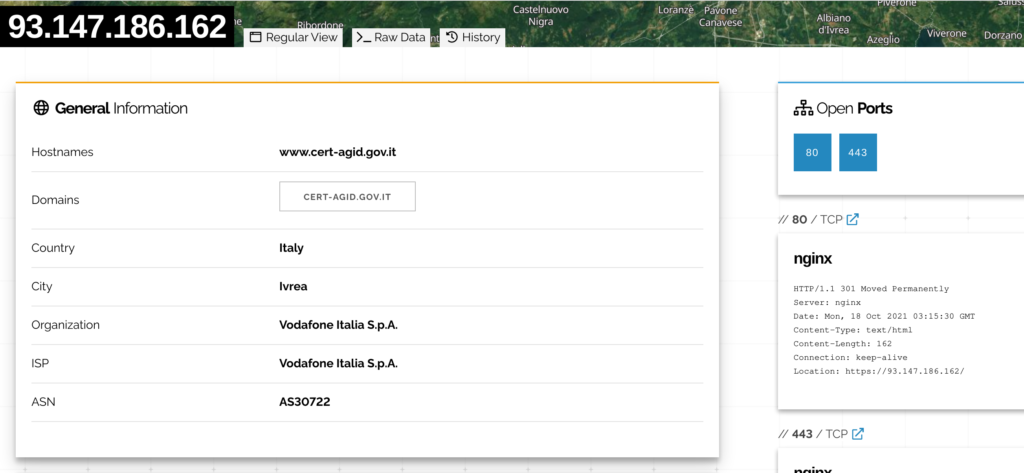
Una funzionalità interessante di Shodan è quella di elencare le vulnerabilità note dei software esposti su una specifica macchina.
Dopo l’analisi delle implementazioni HTTPS e dello stato di aggiornamento dei CMS dei portali della Pubblica Amministrazione risulta interessante utilizzare le informazioni di Shodan per avere una panoramica delle vulnerabilità macroscopiche che la affiggono.
L’utilizzo di Shodan permette di ottenere un buon risultato con il minimo sforzo. E’ sempre possibile costruirsi uno strumento (o utilizzare uno già pronto) per collezionare i banner dei servizi esposti e cercare versioni affette da vulnerabilità ma questo richiede un notevole impiego di tempo (anche solo per l’esecuzione effettiva del collezionamento dei banner) e diverse basi di dati da cui attingere.
Questo articolo è diviso in tre parti: nella prima è spiegato come e quali dati sono stati raccolti, nella seconda viene dettagliata l’analisi e in quella finale sono esposte le conclusioni.
Raccolta dei dati
Anche questa volta il CERT-AGID è partito da IndicePA (IPA), dove sono censiti i siti della Pubblica Amministrazione. Tale portale al momento raccoglie solo i siti istituzionali primari e non sono quindi presenti sottodomini; per aumentare la portata dell’analisi, è stato deciso di usare alcuni tools in grado di identificare sottodomini basandosi su fonti OSINT.
Ad esempio, partendo dal dominio nomedominio.gov.it censito in IPA sono stati scoperti vari sottodomini (webmail.nomedominio.gov.it, portale.nomedominio.gov.it, bustapaga.nomedominio.gov.it, fornitori32.nomedominio.gov.it, …)
Questo passaggio ha portato ad una significativa amplificazione del numero di domini trattati: il numero di domini presenti in IPA è 22.253, il numero di domini ottenuti è stato 401.532. Ovvero un numero 18,04 volte più grande di quello iniziale.
Ai fini statistici e basandoci sulla tipologia di Amministrazione censita in IPA per ogni dominio (i sottodomini ereditano la tipologia del dominio padre) abbiamo diviso la PA in quattro macro aree :
- Sanità e assistenza
- Pubblica Amministrazione Centrale (PAC)
- Pubblica Amministrazione Locale (PAL)
- Istruzione
Lo scopo di questa divisione è verificare eventuali anomalie statistiche in ognuna di queste aree. In particolare se qualcuna risulta più afflitta da vulnerabilità.
Shodan analizza i dispositivi connessi ad internet per mezzo di indirizzi IPv4 e non tramite domini: quest’ultimi infatti possono essere utilizzati solo per un server (la tipica configurazione virtual host).
Per ogni dominio ottenuto è stata fatta un’interrogazione DNS e preso il primo indirizzo IPv4 ritornato: questo permette di creare una relazione n-a-1 tra domini e IP.
Dai 401.532 domini ottenuti sono risultati 62.749 indirizzi IP, in media ogni server (leggi: ogni IP) ospita 6,4 domini. Questo numero non tiene però conto dei domini non risolti (leggi: senza un IP) e può essere inteso solo come un estremo superiore del numero medio di domini per server.
Ottenuta la lista degli IP (ed i metadati necessari a ritrovare i domini corrispondenti) sono state usate le API di Shodan per ottenere l’elenco delle vulnerabilità di ogni IP.
E’ doverosa una nota riguardo la bontà delle informazioni ritornate da Shodan: come indicato sul sito stesso, Shodan determina le vulnerabilità potenziali di una macchina basandosi sulla versione dei software esposti.
La nota sul sito di Shodan è chiara:
Note: the device may not be impacted by all of these issues. The vulnerabilities are implied based on the software and version.
Questo implica che in tutti quei casi in cui la versione pubblicizzata di un software sia volutamente alterata, l’elenco ottenuto non è veritiero.
Inoltre non è possibile determinare l’effettiva sfruttabilità delle vulnerabilità poiché queste possono richiedere interazioni particolari non effettivamente abilitate sul sistema in oggetto (o, più banalmente, potrebbero esservi sistemi IPS che bloccano pacchetti che sfruttano vulnerabilità note).
Nel seguito, per semplificare la lettura, non verrà usato il termine “potenziali” quando si farà riferimento alle vulnerabilità trovate da Shodan.
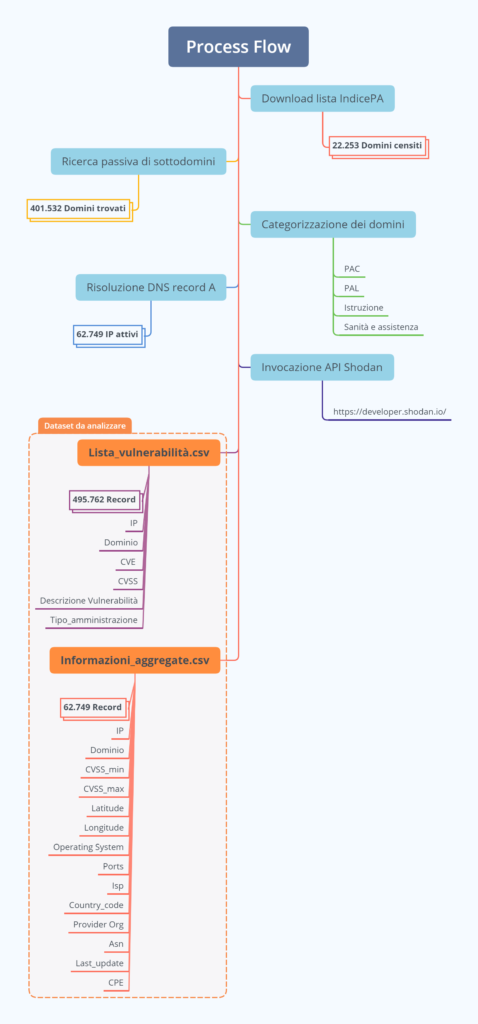
I dati contenuti nei file JSON sono stati mappati, raccolti e organizzati in un dataset in formato CSV per essere successivamente rappresentati in una veste grafica e facilmente consultabile.
I risultati della scansione sono stati divisi in due dataset: il primo contiene le singole vulnerabilità puntuali (per un totale di 495.762 vulnerabilità che affliggono i sistemi della Pubblica Amministrazione nel suo complesso), il secondo contiene una serie di statistiche aggregate (come score CVSS minimo e massimo) di ogni singolo IP.
Mostriamo di seguito un’immagine rappresentante il flusso di lavoro svolto e gli output ottenuti:
Prima di passare all’analisi dei dati, è importante citare le definizioni di CVE, CVSS e CPE in quanto torneranno utili nel prossimo capitolo:
- CVE (Common Vulnerabilities and Exposures) è un elenco di falle nella sicurezza informatica divulgato al pubblico. Quando si fa riferimento a un CVE, si intende in genere una falla di sicurezza a cui è stato assegnato un numero identificativo (ID) CVE;
- CVSS (Common Vulnerability Scoring System) consente alle organizzazioni di valutare le caratteristiche di una vulnerabilità e la sua gravità mediante un punteggio numerico. CVSS v3.0 ha introdotto 5 livelli di classificazione di una vulnerabilità basata sul suo score:
- None -> 0.0
- Low -> 0.1-3.9
- Medium -> 4.0-6.9
- High -> 7.0-8.9
- Critical -> 9.0-10.0
- CPE (Common Platform Enumeration) è un metodo standardizzato per descrivere e identificare classi di applicazioni, sistemi operativi e dispositivi hardware presenti tra le risorse informatiche di un’azienda.
Analisi dei dati
Analisi qualitativa e quantitativa delle vulnerabilità riscontrate
La prima riflessione che ci si pone quando si leggono i dati è sulla gravità delle vulnerabilità riscontrate.
E’ possibile dividere le singole vulnerabilità in base alle categorie (Low, Medium, High, Critical) del loro punteggio CVSS.
E’ bene ricordare che sono categorizzate le vulnerabilità singolarmente riscontrate, quindi per costruzione non è possibile avere la categoria None (che rappresenta l’assenza di vulnerabilità).
In sostanza, il grafico sotto mostra come sono distribuite, in base alla loro gravità, le vulnerabilità trovate ma non dice nulla riguardo la diffusione di tali vulnerabilità sui server della PA.
Si tratta quindi di una visione qualitativa delle vulnerabilità trovate.
Ad esempio, le vulnerabilità critiche sono il 2% del totale ma non sappiamo quanti server siano affetti da almeno una di queste. Il 2% del totale delle vulnerabilità è corrisponde a circa 9.915 unità, quindi è possibile che al massimo tanti siano i server affetti (così come è possibile, ma molto improbabile, che siano tutte riscontrate in un unico server).
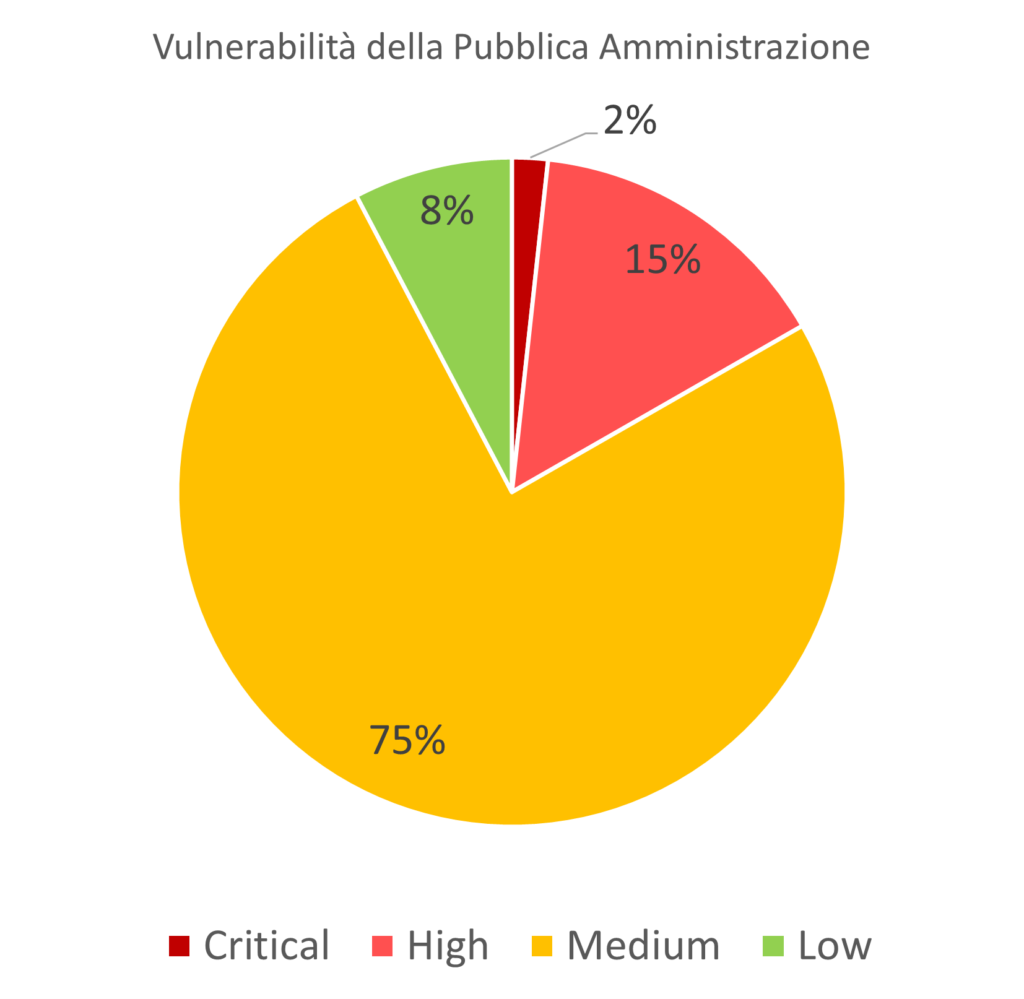
Osservando i risultati, si nota come 3 vulnerabilità su 4 siano di tipo Medium e più di una su 7 di tipo High.
Non è facile farsi un’idea di cosa rappresentino in pratica queste classi di vulnerabilità nella pratica.
Ad esempio la vulnerabilità Medium più diffusa è la CVE-2018-1312, questa riguarda una debolezza crittografica di Apache relativa ad una funzionalità poco usata e che richiede la presenza di macchine clone per essere sfruttata.
Più avanti saranno analizzate meglio il tipo di vulnerabilità in ognuna di queste classi.
Dopo l’analisi qualitativa è possibile passare ad una quantitativa, ovvero misurare quanto sono diffuse, tra i vari server, le classi di vulnerabilità.
Utilizzando i dati aggregati, in particolare il punteggio CVSS peggiore (leggi: più alto) si può risalire al numero di IP che hanno almeno una vulnerabilità Low, Medium, High, Critical e None.
Notare che questa volta compare la classe None poichè sono analizzati i singoli IP (i quali possono non avere vulnerabilità rilevate).
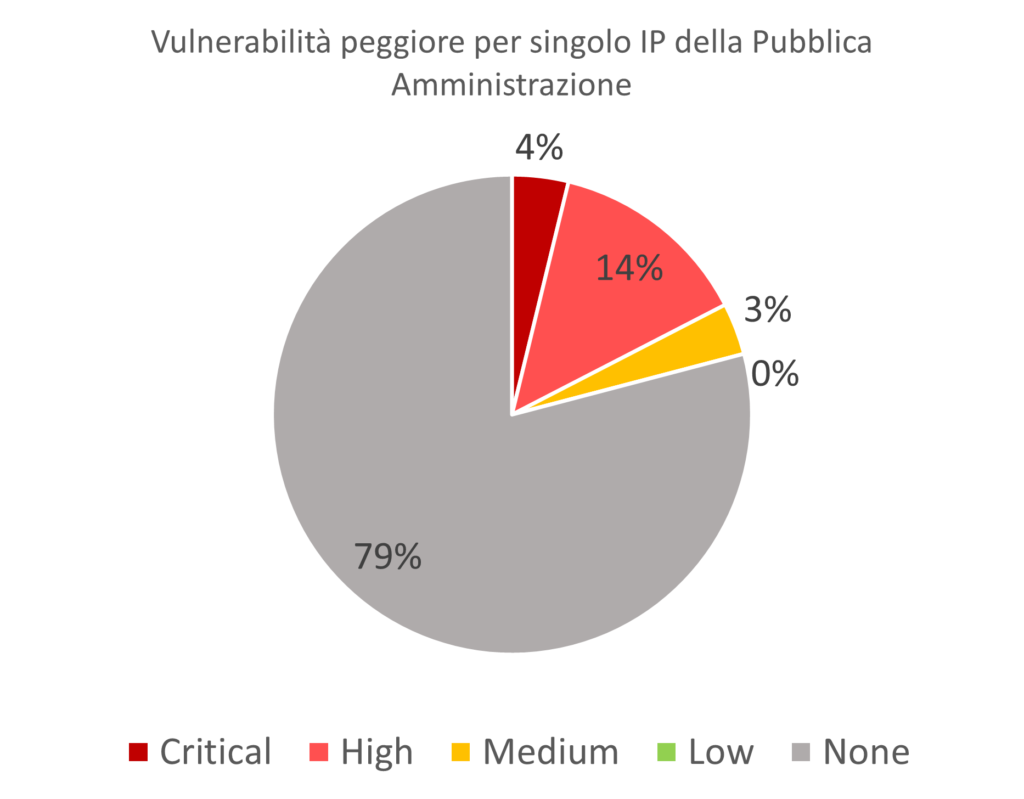
Questo grafico mostra come fortunatamente quasi 4 server su 5 (79%) non presentino vulnerabilità, quindi potenzialmente solo il 20% dei server della Pubblica Amministrazione è vulnerabile.
Si può notare come la sezione più grande della torta, esclusi i server senza vulnerabilità (sezione in grigio), faccia riferimento a vulnerabilità di tipo High con un valore del 14% (8.784 unità).
In media, selezionando casualmente 7 server della Pubblica Amministrazione dalla lista di IP, uno di essi ha buona probabilità di avere una vulnerabilità High.
Comparando il grafico qualitativo precedente con il presente, si osserva che sebbene le vulnerabilità di tipo Medium siano il 75% del totale delle vulnerabilità, esse tendono ad essere MOLTO concentrate.
Per ogni classe di vulnerabilità possiamo calcolare la classe di incidenza sui server affetti e sul totale dei server, ottenendo la tabella sotto:
| Classe | Diffusione media tra i soli server affetti* | Diffusione media tra tutti i server |
| Critical | 3 su ogni server | Un server su 25 |
| High | 4 su ogni server | Un server su 7 |
| Medium | 2 su ogni server | Un server su 33 |
| Low | 1 su ogni server | Un server su 250 |
* I server affetti sono quelli che hanno come massima vulnerabilità riscontrata una vulnerabilità nella classe indicata dalle rispettive righe.
Le vulnerabilità critiche tendono a presentarsi circa tre volte per ciascun server affetto. Lo sforzo richiesto per sanare tali server è quindi individualmente significativo ma comunque poco diffuso (pochi server – molto vulnerabili).
Pericolosità delle vulnerabilità
Stabilita la diffusione qualitativa e quantitativa delle vulnerabilità è poi necessario chiedersi cosa può fare un malintenzionato quando si trova di fronte ad un server vulnerabile.
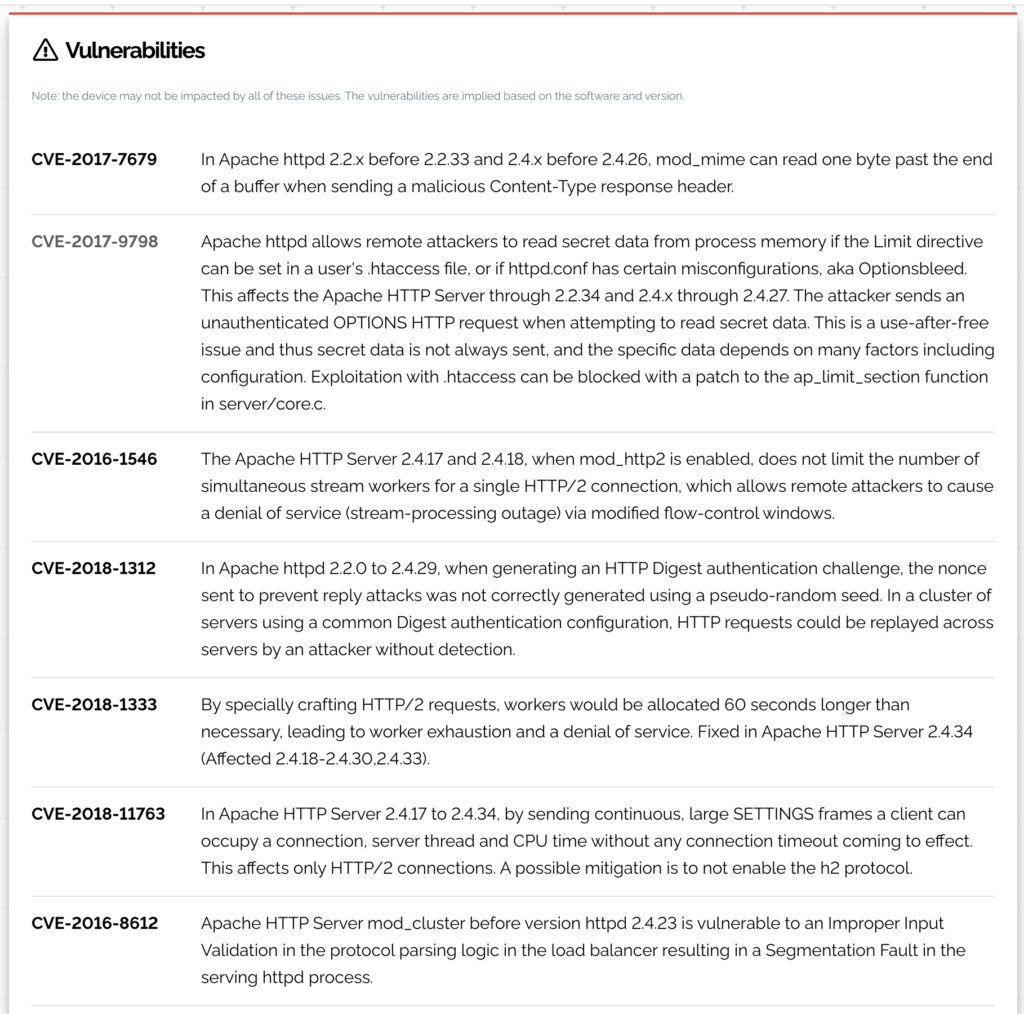
Di seguito sono mostrate le prime tre vulnerabilità, per numerosità, di ogni classe.
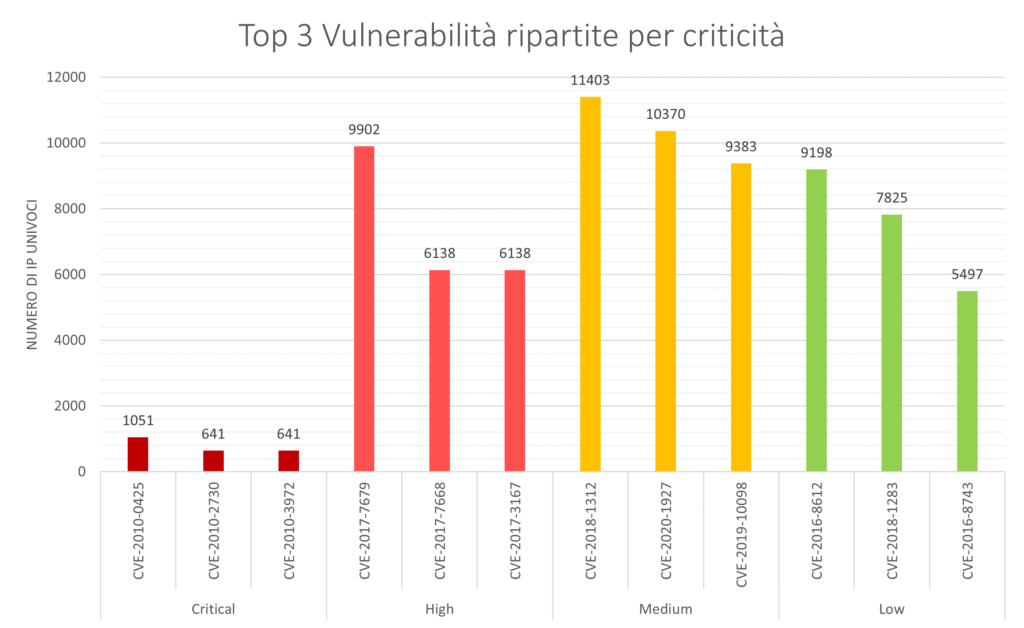
Tutte le vulnerabilità di grado High, Medium e Low sono riconducibili al servizio web server Apache.
Quelle Critical invece sono ripartite su tre servizi: Microsoft FTP Server, Microsoft IIS e di nuovo Apache HTTP server.
Descrivere una vulnerabilità mediante un livello testuale di criticità come Critical, High, Medium e Low può essere riduttivo, per cui riportiamo una tabella con parametri più comprensibili:
| CVE | Classe | Impatto | Utilizzabile da | Usabile per attacco ransomware* |
| CVE-2010-0425 | Critical | Esecuzione di codice arbitrario. Usabile da remoto. Nessuna autenticazione richiesta. | Attori ben organizzati ed intenzionati | Sì |
| CVE-2010-2730 | Critical | Esecuzione di codice arbitrario. USabile da remoto. Nessuna autenticazione richiesta. | Chiunque | Sì |
| CVE-2010-3972 | Critical | Esecuzione di codice arbitrario. USabile da remoto. Nessuna autenticazione richiesta. | Chiunque | Sì |
| CVE-2017-7679 | High | Denial of service. Usabile da remoto. Nessuna autenticazione richiesta. | Chiunque | No |
| CVE-2017-7668 | High | Denial of service. Usabile da remoto. Nessuna autenticazione richiesta. | Chiunque | No |
| CVE-2017-3167 | High | Bypass della Basic Authentication. Usabile da remoto. | Chiunque | In specifici contesti, sì |
| CVE-2018-1312 | Medium | Generazione nonce non sicura. Usabile da remoto. Richiede di catturare pacchetti con autenticazioni valide e un cluster di server cloni. | Attori ben organizzati | In specifici contesti, sì |
| CVE-2020-1927 | Medium | Bypass di alcune regole di rewrite e in specifici casi. Usabile da remoto. Nessuna autenticazione richiesta. | Chiunque ma preferibilmente soggetti con conoscenza della configurazione interna del server | No |
| CVE-2020-1927 | Medium | Bypass di alcune regole di rewrite in specifici casi. Usabile da remoto. Nessuna autenticazione richiesta. | Chiunque ma preferibilmente soggetti con conoscenza della configurazione interna del server | No |
| CVE-2016-8612 | Low | Denial of service Utilizzo da rete locale. Nessuna autenticazione | Dipendenti | No |
| CVE-2018-1283 | Low | Modifica dei parametri passati a script CGI. Funzionalità non attiva di default. Usa una tecnologia obsoleta. | Chiunque | No |
| CVE-2016-8743 | Low | Può confondere servizi middleware in rari casi. Usabile da remoto. Nessuna autenticazione richiesta. | Chiunque ma preferibilmente soggetti con conoscenza della configurazione interna del server | No |
* Tutte le vulnerabilità possono essere usate in ogni tipo di attacco (inclusi i ransomware). Gli attacchi sono generalmente composti sfruttando una serie di vulnerabilità che, prese singolarmente, appaiono poco gravi. Questo campo indica se la vulnerabilità da sola è sufficiente ad attirare l’attenzione di attori criminali che veicolano ransomware (dato il suo potenziale).
Età delle vulnerabilità
Dalla tabella sopra si nota che le vulnerabilità critiche sono in genere datate (si arriva al 2010), quindi, per ulteriore curiosità, vediamo come sono distribuite le vulnerabilità per anno di scoperta:
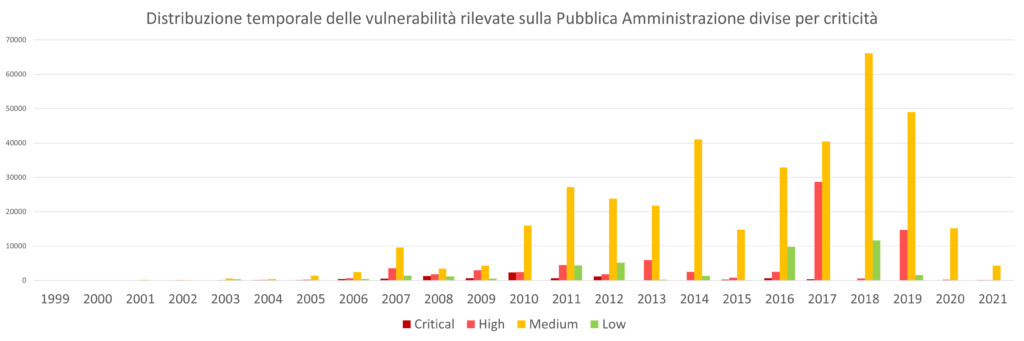
Le vulnerabilità di tipo critico sono state scoperte principalmente negli anni 2008, 2010 e 2012.
Per quanto concerne le CVE categorizzate come High, quelle più comuni fanno riferimento agli anni 2007, 2011, 2013, 2017 (con un picco facilmente distinguibile) e 2019 (con un secondo picco).
L’importanza di questa statistica non è mostrare la distribuzione temporale delle CVE rilevate bensì focalizzarsi sul problema dell’obsolescenza del software e della sua manutenzione.
Dai dati si evince che la Pubblica Amministrazione ha un evidente problema di aggiornamento del proprio parco software.
Basti osservare che, come conferma il fondo scala del grafico, sono state ancora rilevate vulnerabilità scoperte nel 1999 (8 di tipo Critical, 12 di tipo High e 34 di tipo Medium).
Analogamente, si riscontrano 6 vulnerabilità critiche scoperte nel 2000 e 70 vulnerabilità High scoperte tra il 2000 e il 2001.
Ancora una volta il tallone di achille della Pubblica Amministrazione sembra essere la mancata pianificazione dei processi di aggiornamento del software utilizzato.
Questo tipo di pianificazione è, paradossalmente, una misura di sicurezza più semplice di altre da realizzare, come “defence in depth”, “sicurezza multi-livello”, certificazioni o altre misure più estensive e costose
Sembra quindi evidente che basterebbe uno sforzo semplice per migliorare notevolmente la situazione.
Analisi quantitative delle vulnerabilità per ogni classe di PA
Dopo aver analizzato la distribuzione e la diffusione delle vulnerabilità sul totale dei server della Pubblica Amministrazione, ripetiamo il processo su ognuna delle quattro categoria individuate precedentemente: PAC, PAL, Istruzione e Sanità.
Questa analisi può risultare utile ad individuare quali aree necessitano di maggior intervento:
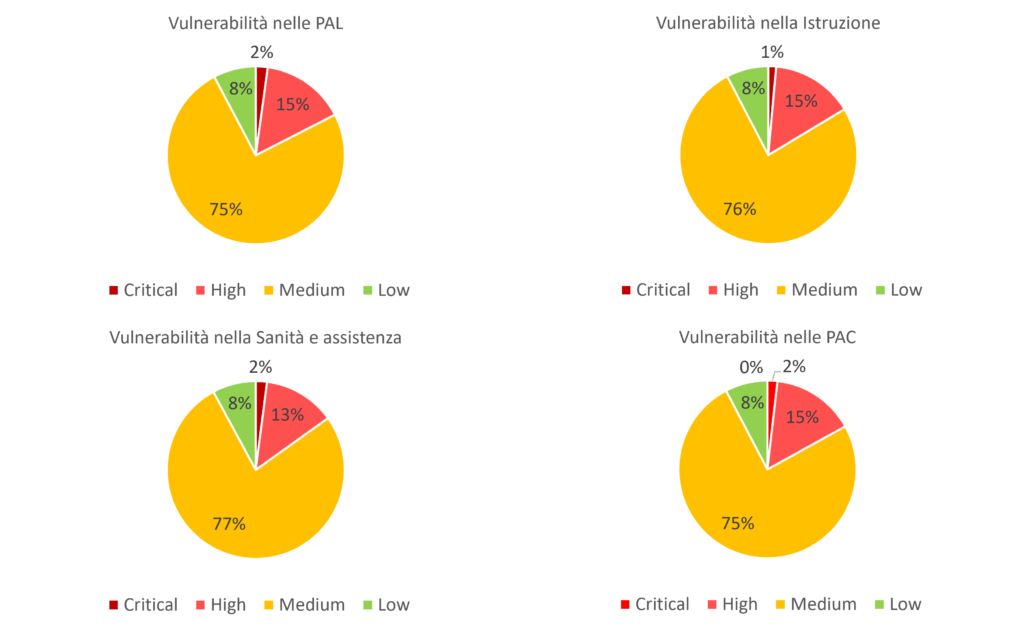
I grafici a torta, contrariamente alle aspettative, non mostrano valori fuori scala. L’osservazione di tali grafici dimostra come tutta la Pubblica Amministrazione, senza distinzione di tipo, patisce le stesse problematiche ed ha la stessa distribuzione delle vulnerabilità. L’unica sottile differenza si nota nel grafico relativo al numero di vulnerabilità presenti sui sistemi della “Sanità e assistenza”: in questo caso, il numero di vulnerabilità critiche scende al 13%, mentre quelle di tipo medie sale al 77%.
Considerazioni geografiche
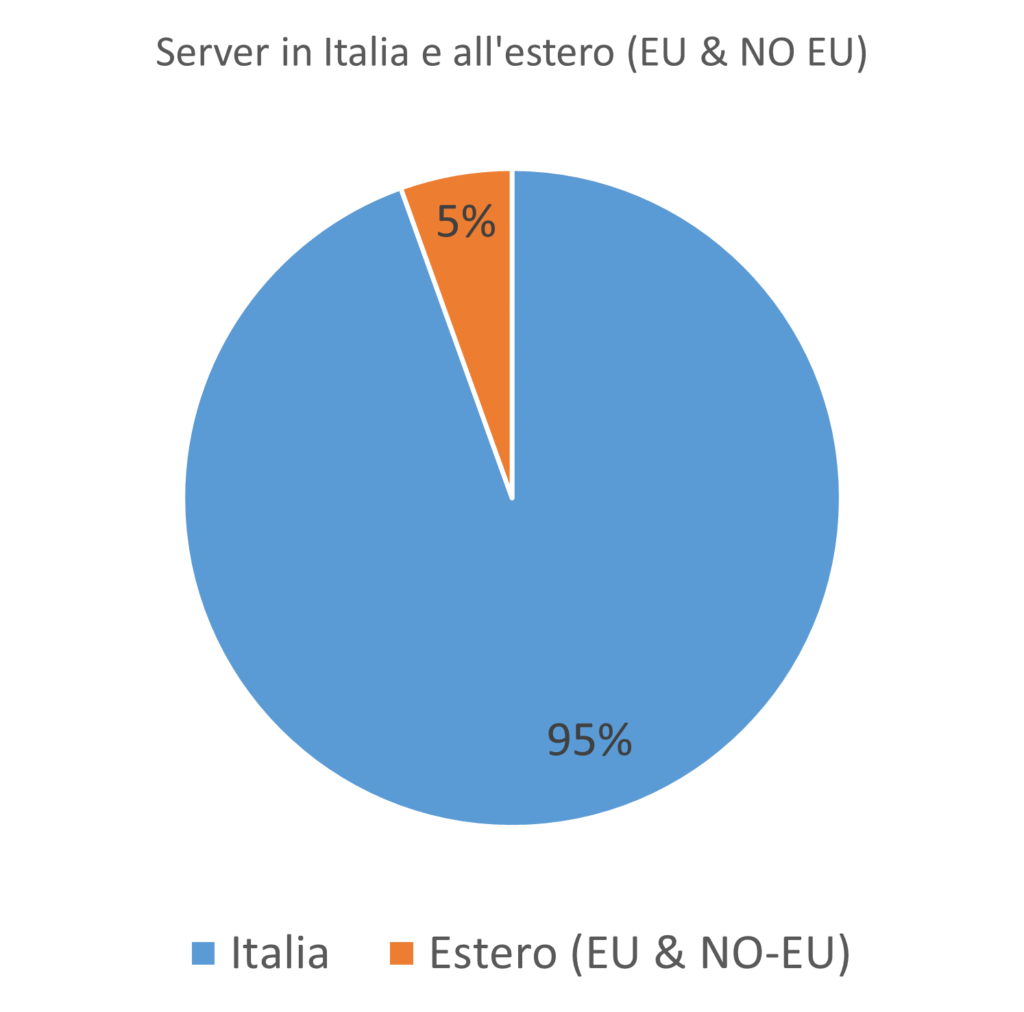
L’aver estratto le coordinate geografiche ed il paese di appartenenza degli IP della Pubblica Amministrazione italiana, ci ha permesso di analizzare anche la loro posizione geografica. Nel grafico a torta di osserva come la maggior parte degli IP risieda nel territorio italiano e soltanto il 5% degli IP viene localizzato su territorio estero EU ed extra EU.
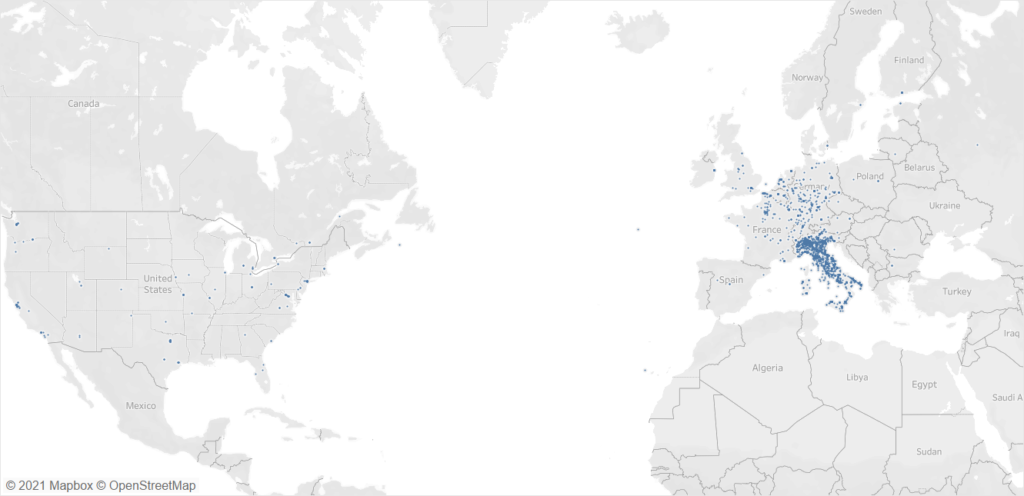
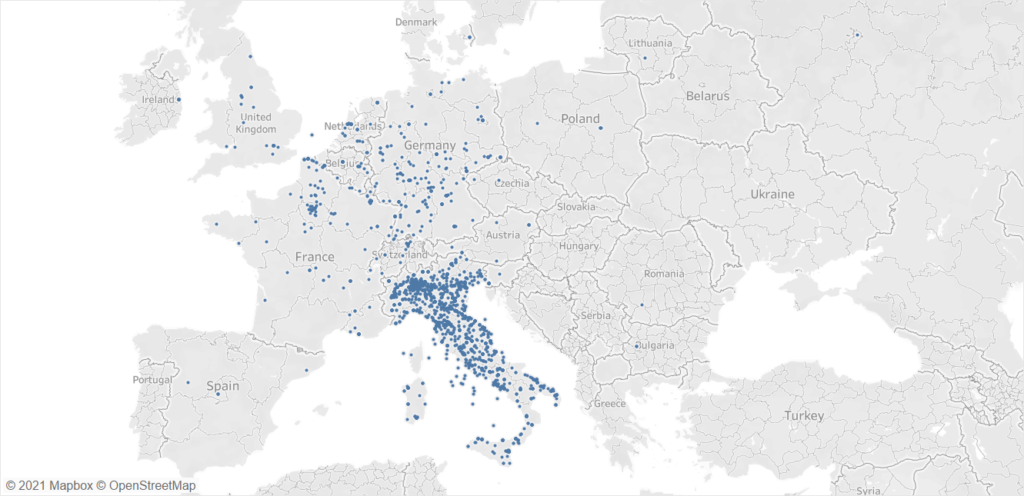
Fatto curioso ma che non sorprende: non ci sono molti server della Pubblica Amministrazione sulle Alpi.
All’interno del territorio nazionale, l’Italia è stata divisa in 3 parti: Nord, Centro e Sud basandosi univocamente sulla latitudine (per semplicità di processo, l’altezza del rettangolo geografico che contiene l’Italia è stato diviso in tre parti di uguale altezza).
Questo ci ha permesso di estrarre un dato puramente statistico / informativo su dove sono geolocalizzati principalmente i server della Pubblica Amministrazione:
- Nord Italia: 46.148 IP
- Centro Italia: 12.310 IP
- Sud Italia: 1.648 IP
Interessante notare come il maggior numero di server sia concentrato a nord e diminuisca scendendo via via verso sud.
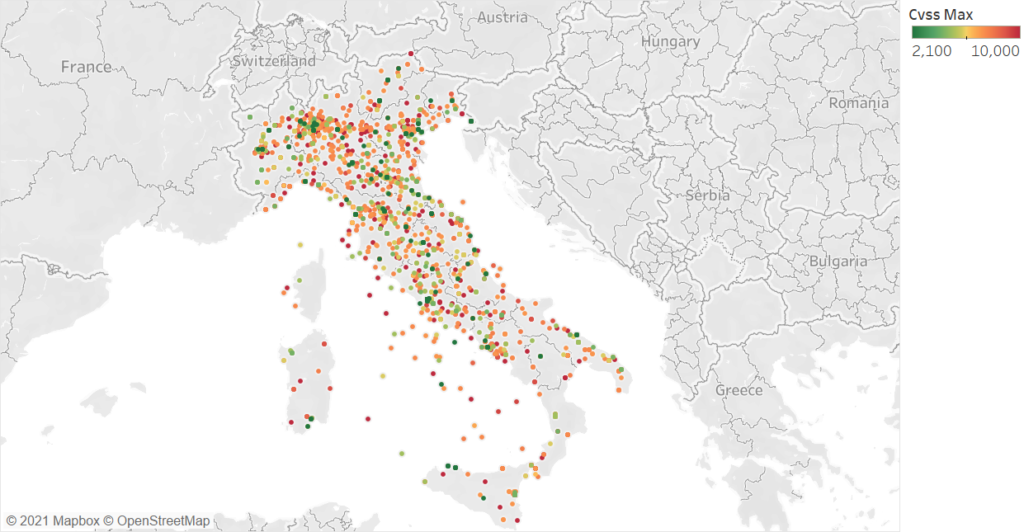
Altra considerazione utile, rappresentata nel grafico successivo, è la distribuzione della gravità di vulnerabilità nelle tre aree geografiche individuate.
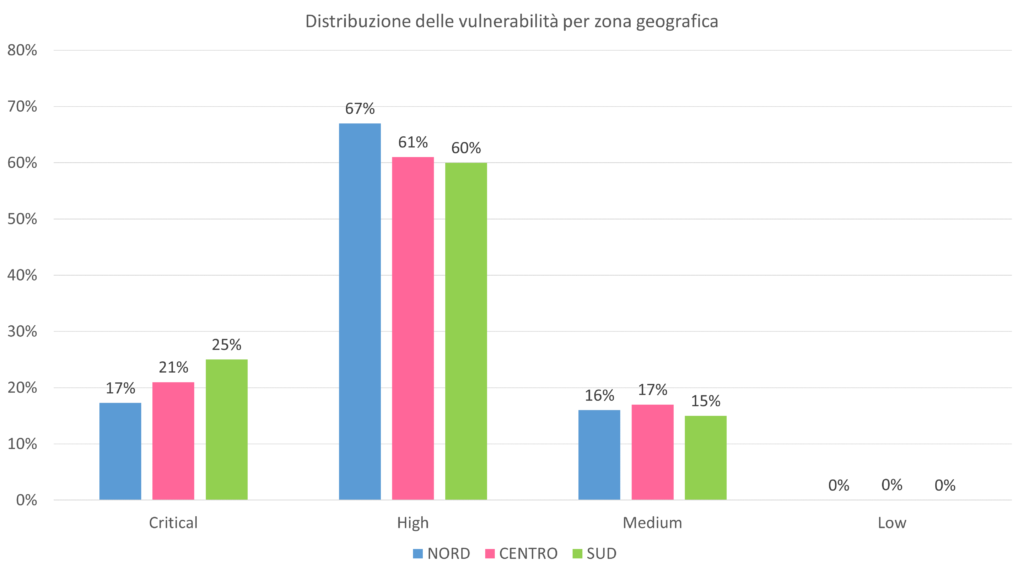
I dati dimostrano che non vi sono variazioni significative tra Nord, Centro e Sud riguardo la gravità delle vulnerabilità. In questo momento tutta la Pubblica Amministrazione presenta lo stesso, omogeneo, livello di rischio.
Continuando con l’analisi dei dati, uno dei dettagli più interessanti estrapolato dai dataset, insieme a quello delle vulnerabilità, è il conteggio delle porte aperte sui 62.749 IP considerati. Si nota subito una strana particolarità:
- vi è un numero altissimo di porte aperte relativo alla 8008, 8010, 8015;
- nella lista emergono porte con servizi considerati deprecati come Telnet (porta 23) o FTP (porta 21);
- rileviamo porte aperte relative a servizi come MySQL (porta 3306) o RDP (Remote Desktop Protocollo – porta 3389).
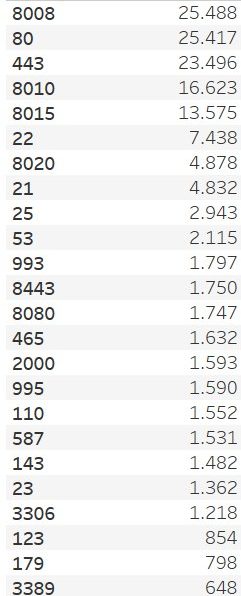
Ricordiamo che i servizi esposti su internet non necessari possono essere veicolo di attacchi di tipo bruteforce, attacchi a dizionario o exploit. Bisognerebbe quindi garantire una corretta esposizione dei servizi e apertura delle porte utilizzate configurando opportunamente i firewall o effettuando il corretto binding degli applicativi sui server.
Considerazioni sui sistemi operativi e software usati
Grazie alle dettagliate informazioni raccolte, è stato possibile anche calcolare statistiche sui sistemi operativi e sugli applicativi software usati.
Tale statistica può essere molto utile per indirizzare la stesura di linee guida, pubblicazioni specifiche e prioritizzazione di corsi sull’hardening dei sistemi operativi.
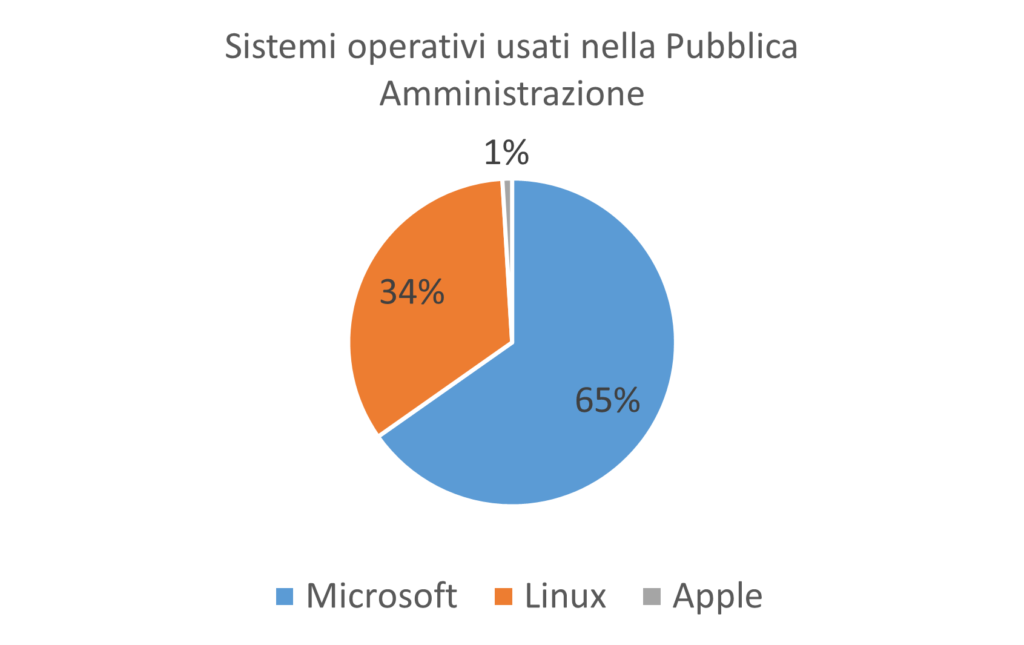
Ad esempio, i corsi di hardening Linux (vedi SELinux), sebbene molto interessanti, non aiuterebbero che poco più di un terzo della PA.
Data la situazione attuale è più utile un expertise su Windows che su Linux. In ottica di una facilitazione di passaggio al Cloud della PA è quindi opportuno considerare che il principale sistema operativo usato dalla Pubblica Amministrazione è ad oggi Microsoft Windows.
Quando la strategia di utilizzo del Cloud nella PA attecchirà, la situazione potrebbe probabilmente cambiare.
Analogamente, è possibile avere una panoramica dei software più utilizzati:
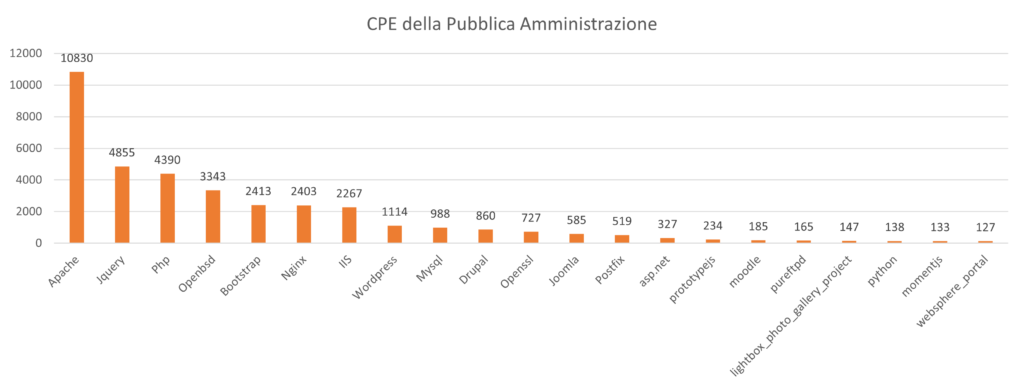
E’ evidente la dominanza di Apache (che risulta usato 4 volte tanto Nginx e IIS).
Risalta all’occhio che, pur essendo Linux l’ambiente di riferimento per Apache e PHP non risulti questo il sistema operativo più utilizzato: potrebbe essere anche questo un fattore che tende ad ingessare il processo di svecchiamento dei sistemi presi in considerazione.
Conclusioni
I dati emersi evidenziano una situazione preoccupante sullo stato di salute dei sistemi della Pubblica Amministrazione con server e applicativi molto obsoleti.
D’altro canto, in questa ricerca, è opportuno sottolineare che per ovvii impedimenti di natura tecnica, non si è potuto analizzare quali PA siano effettivamente protette da sistemi di protezione perimetrali di tipo firewall, waf, proxy, CDN e simili. La presenza dei sistemi citati è una condizione necessaria ma non sufficiente a garantire un livello migliore di sicurezza in quanto questi apparati, se presenti, devono essere configurati opportunamente e correttamente sulle necessità dell’Amministrazione e dei suoi servizi erogati.
Dato l’alto numero di server coinvolti, risulta difficile credere che ognuno di essi non sia stato aggiornato solo per questioni tecnologiche. E’ probabile invece che questi server siano, per molti aspetti, facilmente aggiornabili: una maggiore attenzione su questo fronte potrebbe migliorare la prospettiva in termini di sicurezza informatica della Pubblica Amministrazione in modo determinante, ottenendo anche dei vantaggi nel rapporto tra investimenti/ritorno di risultato, abbattendo il livello di rischio legato alla diminuzione della superficie di attacco esposta ed i danni derivanti dagli attacchi subiti ed andati a buon fine.
Considerando la crescente diffusione del fenomeno dei ransomware in forme sempre più organizzate, bisogna necessariamente adeguarsi a standard di sicurezza più elevati per contrastare meglio questa ed altre piaghe che si presenteranno con maggior frequenza nel futuro prossimo.