YAU – Parte 4 – Primo stadio e la sezione bss
yau
Nell’ultimo articolo avevamo visto come ottenere il payload contenuto nel packer. In alcune occasioni il payload è risultato essere un’eseguibile PE ma nei campioni recenti (e in quelli del 2018) è una DLL.
Indipendentemente dal tipo di PE, l’esecuzione procede nello stesso modo; sono presenti alcune variazioni ma sono dettagli minori di implementazione.
Vedremo che questo payload, denominato “primo stadio”, è in realtà un packer che presenta alcune importanti caratteristiche:
- Non utilizza offuscazione CFO o fa uso di runtime. Risulta quindi è piuttosto semplice da analizzare.
- Fa uso di una tecnica per l’offuscazione della sezione bss che verrà riusata negli stadi successivi. A tal proposito vedremo come scrivere uno strumento per la decodifica automatica.
- Fa uso dei “JJ chunk”, un modo per salvare dati strutturati nell’eseguibile.
Questi saranno oggetto del prossimo articolo, dove oltre la descrizione verrà affrontata la questione dell’estrazione automatica.
YET ANOTHER URSNIF

Questo è il quarto di una seria di articoli, tutti raggruppati qui.
Indice
Parte 1, Le e-mail e il documento Excel
Parte 2, Le macro
Parte 3, Il packer
Parte 4, Primo stadio e la sezione bss <–
Parte 5, Ancora il primo stadio e i “JJ chunk”
Parte 6, Il secondo stadio e i primi IoC
Parte 7, Il secondo stadio, seed, GUID e privilegi
Parte 8, Il secondo stadio, configurazione e download
Parte 9, Il secondo stadio, salvataggio dei moduli e persistenza
Parte 10, Rimozione di Ursnif
Parte 11, Il client, inizializzazione e configurazione
Parte 12, Il client, da powershell ad explorer.exe ai browser
Parte 13, Il client, comandi e trasmissione al C2
Parte 14, Il C2, panoramica
Parte 15, Il C2, i sorgenti e l’architettura
Parte 16, Il C2, vulnerabilità
Parte 17, OSINT e resoconto finale
Preambolo
L’esecuione inizia dall’entry-point PE. Analizzeremo principalmente i sample recenti ma indicheremo eventuali differenze con i campioni meno recenti.
L’esecuzione inizia con un po’ di codice di “bookkeeping” che crea un heap, un contatore atomico per tenere traccia delle instanze e un flag per indicare se il malware è in esecuzione.
L’esecuzione poi procede in un thread in background.
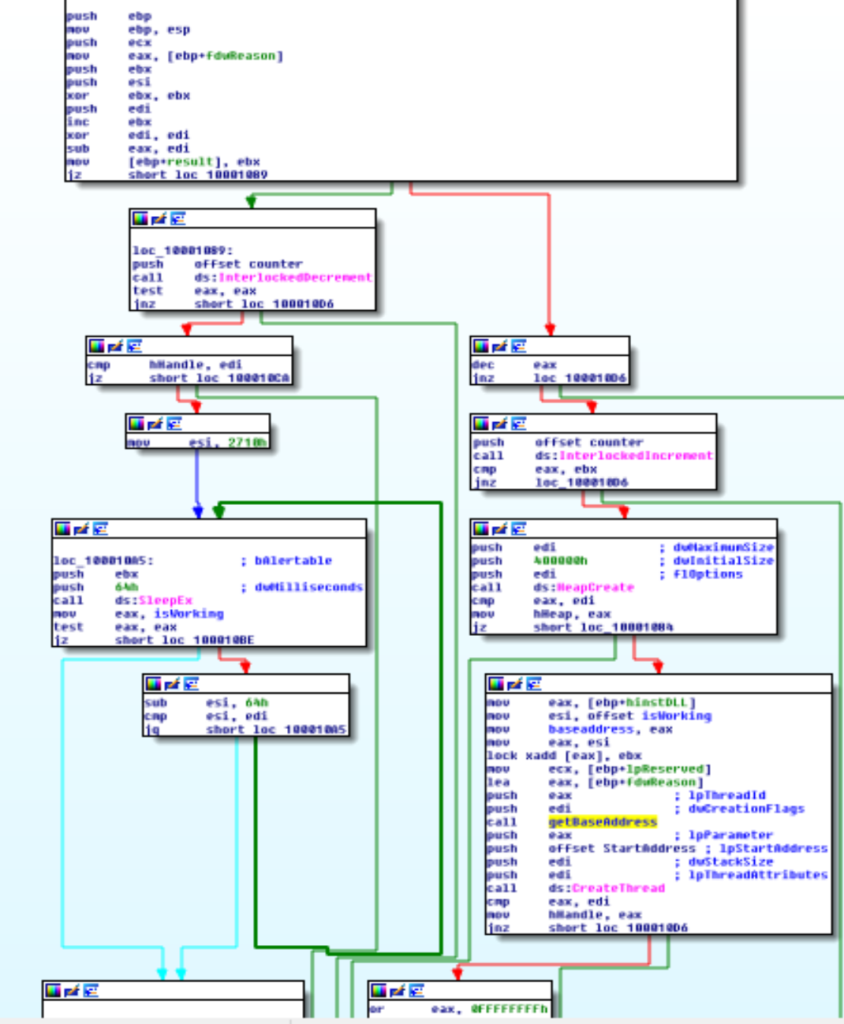
In particolare questo stadio effettua i seguenti passi (facilmente riconoscibili dalla figura sopra) quando viene caricato in memoria (DLL_PROCESS_ATTACH)
- Viene incrementato il numero di instanze in esecuzione. Se ve ne è già una, i restati passi sono saltati.
- Viene creato un heap di 4MiB.
- Viene recuperato il base address della DLL (vedi sotto).
- Viene impostato un flag di lavoro al valore 1.
- Viene creato un thread per proseguire l’infezione.
Nel momento in cui la DLL viene rimossa dalla memoria (DLL_PROCESS_DETACH) sono eseguiti i seguenti passi:
- Viene decrementato il numero di istanze in esecuzione. Se questa non è l’ultima i restanti passi vengono saltati.
- Se era stato creato il thread in fase di inizializzazione, attende al massimo 10 secondi che finisca (viene controllato il flag di lavoro).
Le pause vengono fatte in intervalli di 64 ms. - Viene distrutto l’heap creato in inizializzazione.
Nelle versioni di metà 2020 il thread in background era avviato sempre con CreatThread ma facendo puntare la routine di partenza all’API Sleep.
Un’APC era poi aggiunta al thread (tramite QueueUserAPC) per continuare l’infezione.
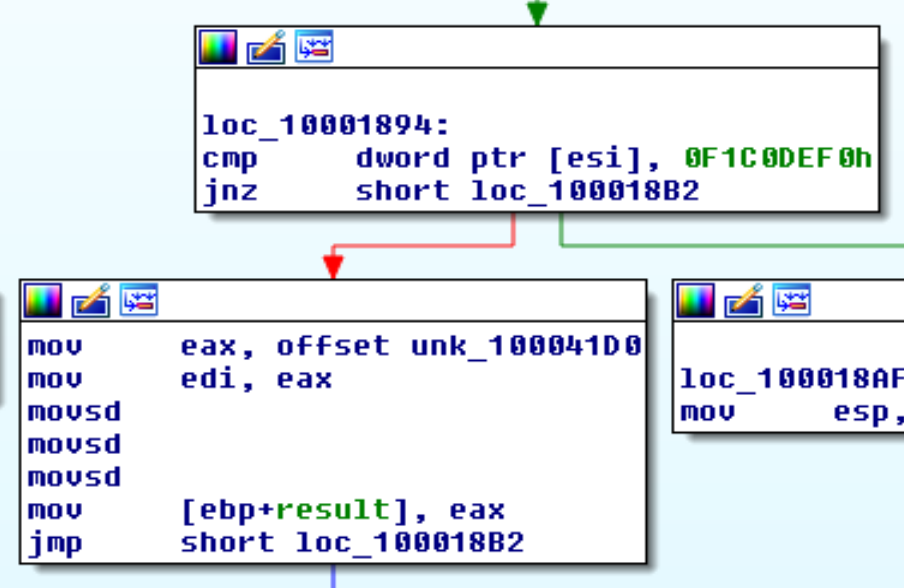
Il base address della DLL è recuperato tramite il parametro lpReserved di DllMain, che risulta essere il base address della DLL.
Se la firma al base address non è MZ, viene controllato se questa equivale comunque al valore 0xF1CODEF0 (che sembra una costante scelta per lo spelling) e come base address viene ritornato un buffer riempito con i primi 16 byte copiati dal base address.
Nei sample recenti è esportata anche la funzione DllRegisterServer, la quale contiene una chiamata a WaitForSingleObject.
Viene atteso, con timeout infinito, la terminazione del thread di lavoro.
Nei sample precedenti questo era fatto in inizializzazione.
Il thread di lavoro
La procedura di avvio del thread di lavoro è molto semplice e contiene il codice di gestione del flag di lavoro.
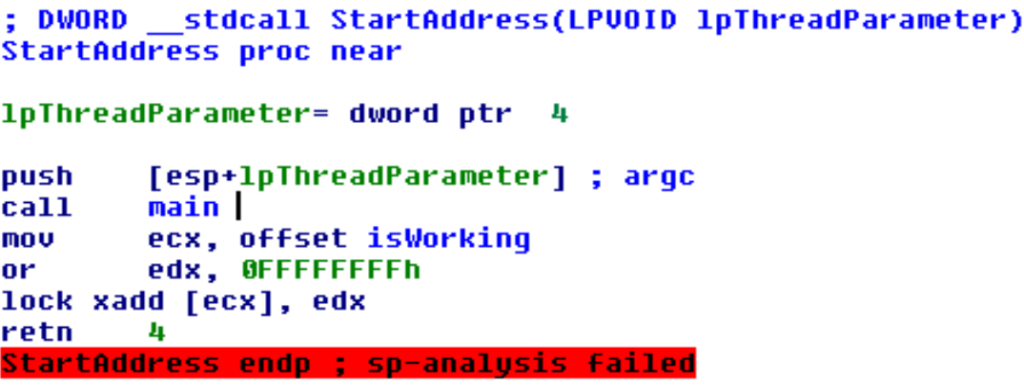
La funzione main è piuttosto semplice e sebbene presenti del codice superfluo (probabilmente mai ripulito dagli autori) i suoi compiti sono solo due: estrarre il payload (una DLL) ed eseguirlo.
L’inizio del thread di lavoro è riportato qui sotto.
La funzione createEventAndOpenSelf crea un evento anonimo che non verrà mai usato. Inoltre, se la versione di Windows è successiva alla 5.0 (ovvero da Windows XP in poi), viene ottenuto un handle al processo in esecuzione. Anche questo handle non verrà mai usato.
Se createEventAndOpenSelf ritorna un codice di errore, cosa possibile solo su versioni di Windows precedenti a XP, il malware interrompe l’infezione.
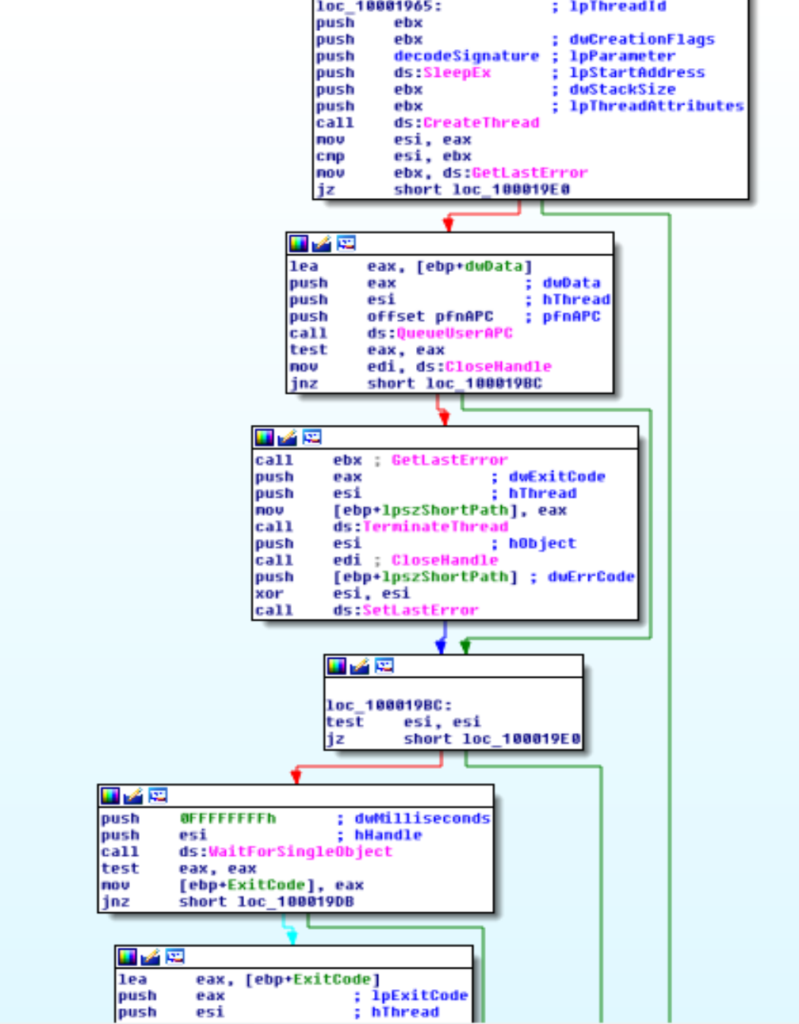
A questo punto il malware effettua le seguenti azioni:
- Decodifica la sezione bss.
- Ottiene il nome della DLL del packer visto nell’articolo precedente (ed usa
GetLongPathNameWper ottenere il nome lungo, sembra una chiamata inutile dato che il nome restituito non è in formato 8.3). - Crea un thread che punta all’API
Sleepe vi accoda un’APC con il codice che continua l’infezione. - Attende la terminazione del suddetto thread ed esce.
La decodifica della sezione bss
In tutti i sample la sezione bss è “cifrata”. L’algoritmo di decifratura è rimasto stabile fino a qualche tempo fa.
Nei sample recenti è cambiato leggermente (un meno ed un più sono stati scambiati).
Nei sample più vecchi della metà del 2020 la sezione bss era decodificata “al volo” tramite un exception handler (che la ricodificata subito dopo).
Nei campioni recenti è decodificata una volta per tutte all’inizio.
Può essere utile partire dai sample recenti e poi sottolineare le differenze con quelli più vecchi.
La prima cosa da notare è che la funzione che decodifica bss accetta un parametro in input. Questo verrà usato per derivare la master key per decodificare ogni pagina della sezione bss.
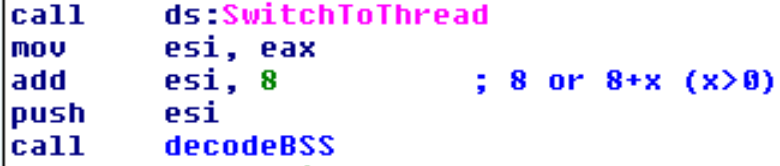
In alcuni sample Ursnif fa dipendere questo parametro da fonti non deterministiche.
E’ il caso del codice mostrato sopra, in altre occasioni la posizione del mouse veniva usata come fonte non deterministica.
In tutte le varianti il dominio del parametro è comunque basso, nel caso sopra è 1 bit (tecnicamente SwitchToThread può ritornare qualsiasi valore ma nelle implementazioni attuati ritorna 0 o 1). Nel caso della posizione del mouse del valore ottenuto solo i 5 bit bassi erano tenuti.
La decodifica della sezione BSS inizia ottenendo l’RVA e la dimensione di questa sezione, dopodichè un buffer di dimensioni adeguate è allocato.
In questo buffer avverrà la decodifica e sarà poi successivamente scritto al posto dei dati della sezione BSS (vecchi sample) o usato direttamente (sample recenti).
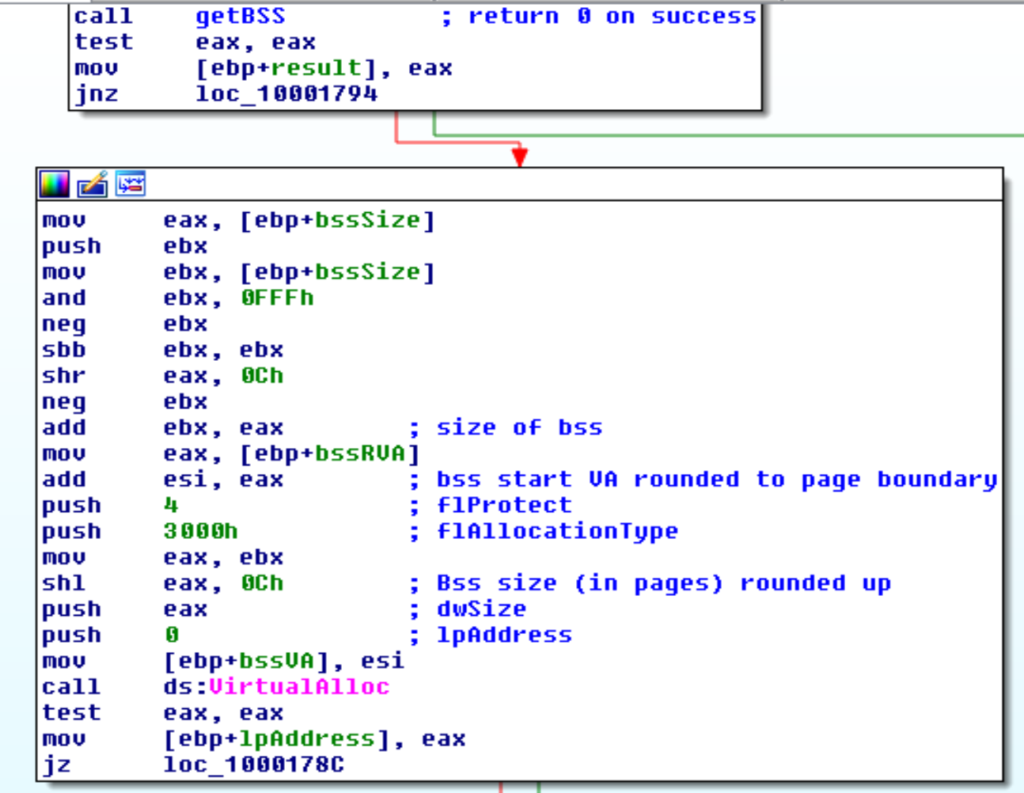
La decodifica avviene creando una master key, questa sarà poi modificata per ogni singola pagina della sezione bss.
La master key deriva da una stringa contenente la data della campagna.
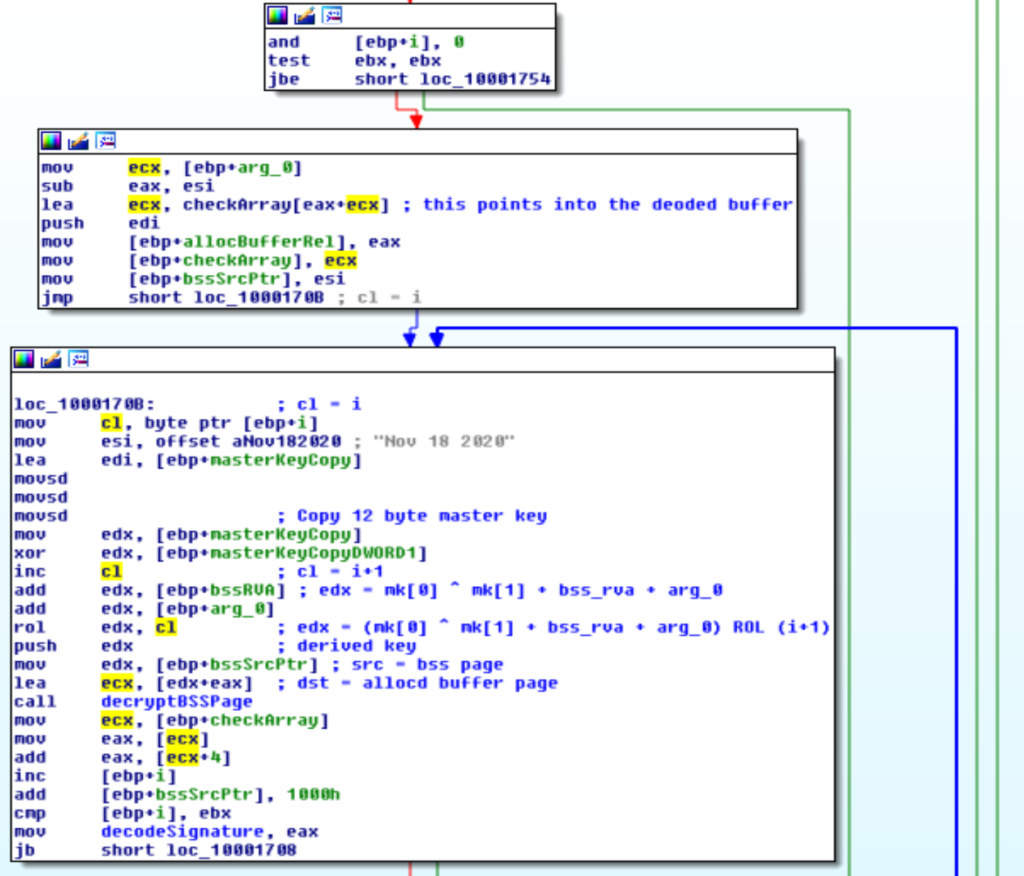
Dal codice si evince facilmente che la master key è ottenuta come:
date = (DWORD*)"Nov 18 2020";
master_key = (date[0] ^ date[1]) + bss->rva + k;dove k è una costante fissa.
Nei sample recenti è 9, in tutti quelli precedenti è sempre stata 0xe.
Notare che k dipende dal parametro non deterministico in input.
A partire dalla master key, il malware ricava una chiave per ogni pagina della sezione bss con un left rotate pari all’indice (1-based) della pagina.
La prima pagina avrà come chiave ROL(master_key, 1), la seconda pagina avrà ROL(master_key, 2) e così via.
Ogni pagina è decodificata con un semplice algoritmo. Il codice è mostrato sotto.
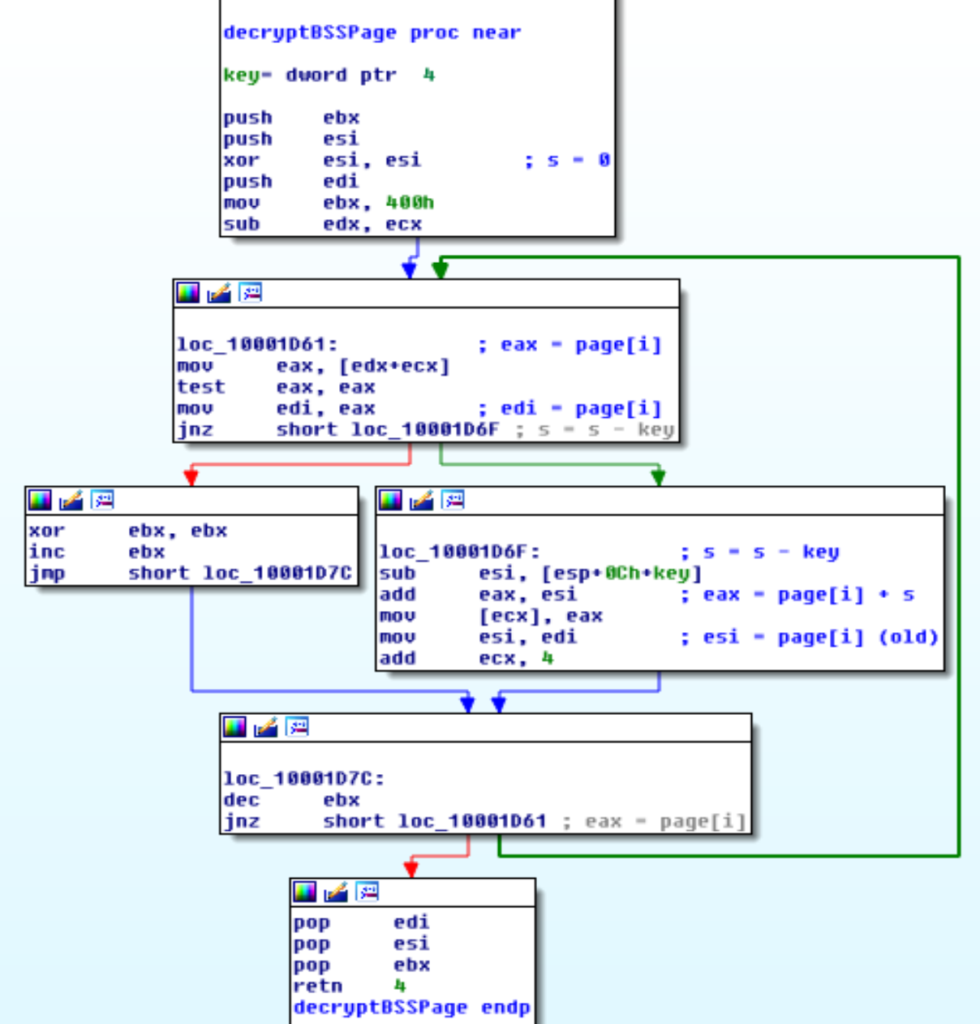
Questo algoritmo è di semplice traduzione in C.
La versione mostrata proviene da un sample recente, i campioni precedenti avevano “s = s + key” e “page[i] - s“, quindi un paio di segni sono stati cambiati.
E’ importante notare come Ursnif usi la somma di due DWORD ad un offset specifico per determinare se la decodifica sia corretta.
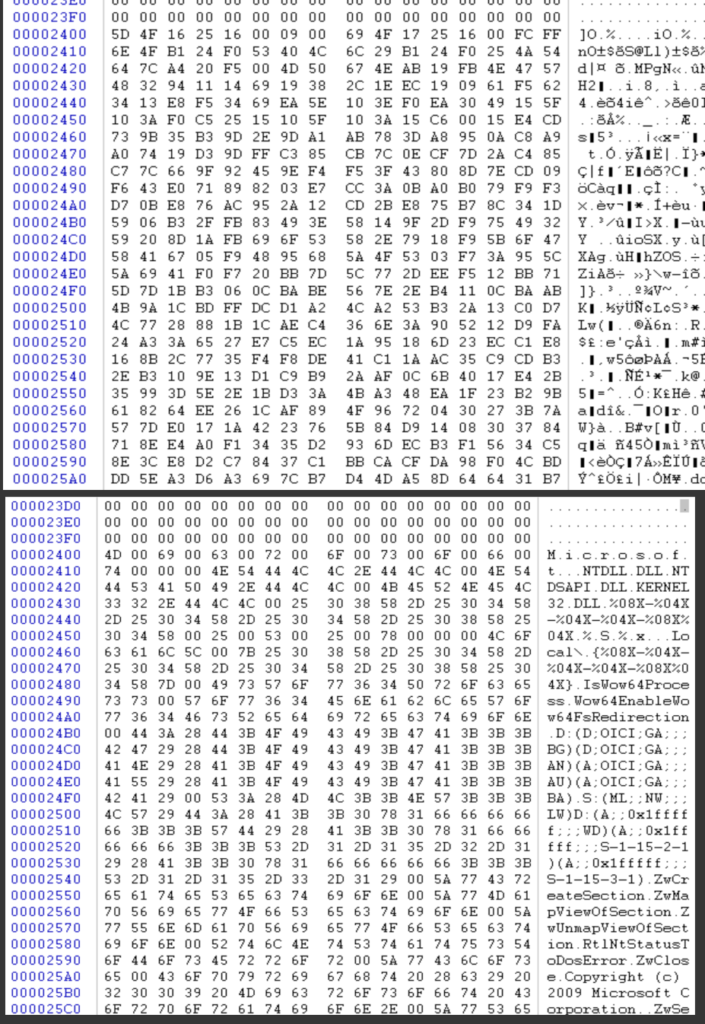
Se ricarichiamo il sample una volta decodificata la sezione BSS, è possibile vedere come queste DWORD si trovino all’interno della stringa “Copyright (c) 2009 Microsoft Corporation.“.
In particolare le DWORD corrispondenti a “ (c)” e “ 200” sono sommate e la loro somma deve risultare 0x59935A40 (cosa possibile solo se la sezione BSS è correttamente decodificata).
Decodifica automatica con ubss
Avendo analizzato l’algoritmo di decodifica, è possibile scrivere un programma che decodifichi automaticamente la sezione bss.
Le unichè difficoltà riguardano: indovinare la costante k, indovinare la variante e riconoscere una decodifica corretta.
Per i primi due problemi si può adottare un approccio bruteforce: il valore di k è sempre stato molto piccolo e le varianti individuate sono solo due.
Per il riconoscimento di una decodifica corretta è possibile cercare una stringa specifica nei dati ottenuti.
Abbiamo scelto “NTDLL.DLL” come stringa di verifica, era possibile usare la stessa utilizzata da Ursnif ma riteniamo che quest’ultima sia più soggetta a variazione.
Il programma di decodifica (ubss) può essere scaricato qui.
Richiede, da linea di comando, il percorso della DLL da decodificare, questa è modificata in-place.
Il programma può essere compilato anche per Linux (non fa uso di API Windows) ed effettua una decodifica statica.
>ubss ursnif.payload0.dll
Decodifica “al volo” della sezione bss
Nei sample fino alla metà del 2020 circa, la sezione bss era decodificata una pagina alla volta e solo quando necessario.
Inizialmente le pagine di questa sezione sono marcate non accessibili, quando un’istruzione accede ad un dato nell’area da decodificare, viene generata un’eccezione.
Un apposito exception handler ripristina i permessi della pagina e la decodifica.
Prima di proseguire con l’esecuzione del codice principale però viene abilitato il flag TF (trap flag).
In questo modo appena eseguita l’istruzione che accedeva ai dati, un’altra eccezione è generata e l’exception handler la usa per ricodificare la pagina precedentemente in chiaro.
Questi sample Ursnif usavano una struttura in cui salvare le chiavi di ogni singola pagina (derivate come visto sopra) e altri oggetti di controllo.
struct bss_controller_t
{
/* 0x00 */ CRITICAL_SECTION mutex;
/* 0x18 */ struct page_info_t* header;
/* 0x1c */ struct page_info_t* tail;
/* 0x20 */ HANDLE exception_handler;
/* 0x24 */ DWORD tlsIndex;
}Il mutex è usato per l’accesso esclusivo alla lista indicata dai campi header e tail. Questa è una doppia lista concatenata che contiene le informazioni di ogni pagina (inclusi chiave e permessi).
E’ inoltre presente l’handle all’exception handler per rimuoverlo e l’indice nel TLS in cui viene salvato l’indirizzo che ha provocato l’eccezione.
L’exception handler è installato con AddVectoredExceptionHandler.
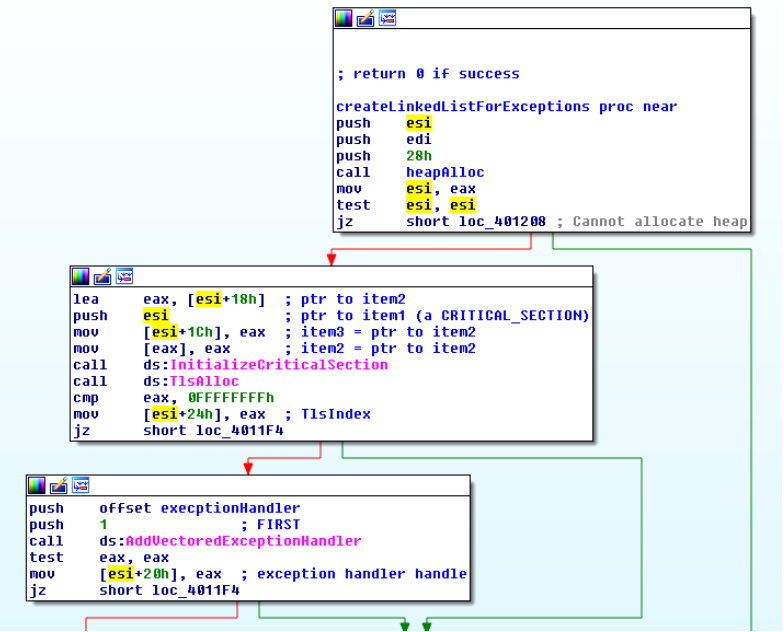
Dopo l’installazione dell’exception handler, il codice enumera ogni pagina della sezione bss e per ognuna crea una struttura apposita che inserisce nella lista concatenata.
struct page_info_t
{
/* 0x00 */ struct page_info_t* next;
/* 0x04 */ struct page_info_t* previous;
/* 0x08 */ uint32_t page_address;
/* 0x0c */ DWORD original_page_protection;
/* 0x10 */ uint32_t page_secret;
/* 0x14 */ uint32_t counter;
}L’exception handler installato gestisce due eccezioni: EXCEPTION_ACCESS_VIOLATION, generata quando un’istruzione accede alle pagina dellazione bss, e EXCEPTION_SINGLE_STEP, generata in seguito all’abilitazione di TF.
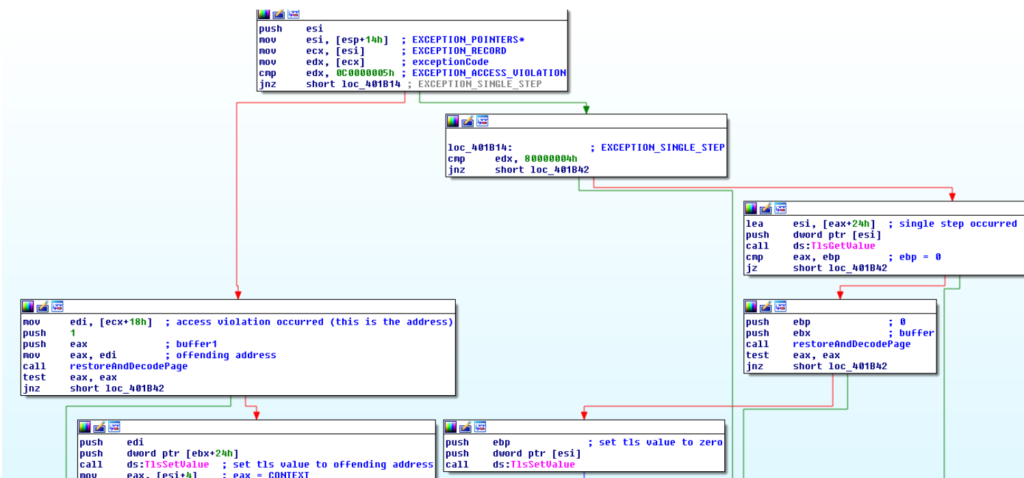
L’algoritmo usato dall’exception handler si può ricavare facilmente, lo riportiamo qui sotto.
1. If exception_code == EXCEPTION_ACCESS_VIOLATION
1.1. Find the node for the faulting address in the linked list
1.2. If the page counter in the node is zero:
1.2.1 Get the original page protection for the faulting page and restore it
1.3. Get the per page secret and decode the faulting page
1.4. Save the faulting address in the tls index
1.5. Increment the counter
2. If exception_code == EXCEPTION_SINGLE_STEP
1.1. Get the faulting address in the tls index
1.2. Find the node for the faulting address in the linked list
1.3. Decrement the counter in page node
1.4. Get the per page secret and encode back the faulting page
1.5. If the page counter in the node is zero:
1.5.1 Get the original page protection for the faulting page and restore itNel prossimo articolo riprenderemo l’analisi dalla procedura APC accodata al thread creato dal malware.
Vedremo come sono decodificati i “JJ chunk” e come prosegue l’infezione.