Come funziona il ransomware Knight – Analisi con l’aiuto di Triton
knight ransomware
Il ransomware Knight, distribuito in Italia tramite una falsa fattura, è Cyclops 2.0. Il gruppo omonimo ha rilasciato a maggio di quest’anno la nuova versione con un nuovo nome.
Stando a quanto è stato pubblicizzato, Knight è in grado di infettare sistemi Windows, Linux (incluso l’hypervisor ESXi) e MacOS. E’ inoltre in grado di esfiltrare file dalle macchine compromesse al fine di sfruttare la classica strategia della double extortion in cui la vittima è spinta al pagamento del riscatto sia per riottenere i propri file che per non vederli pubblicati in rete.
Il gruppo Knight fornisce il ransomware Knight come RaaS
Il modello di business del gruppo non prevede un programma di affiliazione come avviene per altri gruppi ransomware finora osservati. Il software è acquistabile da chiunque e pronto all’uso: solo il componente dedito alla cifratura dei file (il ransomware vero e proprio) viene venduto separatamente da quello atto al furto dei file (lo stealer in gergo). Non è stata infatti rilevata capacità di esfiltrazione dati nello studio del campione analizzato dal CERT-AGID.
Essendo Knight un RaaS, non è sorprendente più di tanto che sia stato diffuso tramite e-mail nella campagna ad inizio di questo mese ma rappresenta comunque una anomalia. I gruppi ransomware più strutturati sfruttano delle risorse apposite per le prime fasi dell’infezione di una vittima (RRAE – Reconnaissance, Resource, Access, Execution) oppure comprano questo servizio da attori esterni (in gergo: IAB – Initial Access Broker, nome che per estensione indica anche personale interno al gruppo stesso). Quello che caratterizza gli IAB è l’utilizzo di malware di tipo infostealer o RAT. Ad esempio, il malware Ursnif, che conosce bene il nostro paese, si è evoluto da Banking Trojan a malware in grado di effettuare Discovery, cioè in grado di ottenere quel genere di informazioni necessarie a determinare il valore della vittima per, si presume, poi operare come IAB.
Questo modo di operare rende difficile percepire la reale gravità della minaccia
Ricevere un ransomware per e-mail è quindi piuttosto insolito: il gruppo Knight però non ha IAB o risorse per ottenere un accesso iniziale ed il suo modello d’impresa si basa sul ricevere delle commissioni sull’operato di altri criminali che comprano e veicolano il loro ransomware come meglio desiderano. È quindi ipotizzabile che attori opportunistici, senza grandi capacità tecniche, tentino la fortuna inviando Knight a quanti più account e-mail possibili.
Le realtà della “macro-cibercriminalità”, caratterizzata da attori persistenti ed avanzati, e quella della “micro-cibercriminalità”, dove gli attori sono opportunistici, si confondono e solo il tempo potrà dire se una nuova campagna ransomware massiva si ripeterà o rimarrà un fenomeno isolato.
Rimane quindi fondamentale l’analisi dei fenomeni ransomware e, più in generale, dei malware (visto che non è possibile scindere completamente i due aspetti) per determinare un quadro più completo delle singole minacce. L’attribuzione e la previsione delle campagne malware sono attività la cui complessità è molto variegata e che richiedono un bagaglio di capacità e risorse non indifferenti, al momento non troppo disponbili.
L’avvio del ransomware e il packer IDAT loader
Le prime fasi dell’infezione sono descritte in dettaglio nell’articolo pubblicato ad inizio mese. Il click su uno dei collegamenti presenti nello ZIP non porta però all’avvio immediato del malware che invece viene diffuso tramite il packer IDAT loader, che ha lo scopo di evitare il rilevamento da parte degli EDR (grazie a Nunzio e Cyb3rWhiteSnake per averci indicato il nome di questo packer).
Questo packer è caratteristico nel suo genere per una serie di TTP peculiari di cui si riportano qui in seguito le caratteristiche principali:
- Si presenta come un’installer (NSIS) o un extractor (WinRAR SFX) che contiene un software lecito ma il cui codice è stato modificato. Ad esempio, nel corso delle analisi del CERT-AGID è stato osservato un installer NSIS che estraeva ed eseguiva un package Python innocuo. L’interprete Python estratto però era stato modificato per eseguire codice malevolo all’avvio. Un altro esempio riguarda l’utilizzo di uno strumento di sincronizzazione di software Adobe con affiancata una DLL del CRT modificata.
- Contiene generalmente stadi multipli in ognuno dei quali viene usato software lecito ma modificato. Questi stadi successivi sono solitamente salvati in un percorso temporaneo.
- I file dello stadio successivo, con il loro nome, sono presenti in memoria in un BLOB di dati.
- Il BLOB cifrato può essere recuperato da un URL o da un file locale (estratto dall’installer o da uno stadio precedente). Si presenta sottoforma di PNG il cui contenuto (compresso) dei chunk
IDAT(da cui il nome) sono i byte del BLOB.
Lo stadio finale del packer estrae ed esegue il ransomware Knight in memoria.
La WinMain del ransomware
Alcune caratteristiche sono ben documentate nella pagina di descrizione dello stesso ransomware pubblicata dal gruppo Knight, come ad esempio le modalità supportate ed il tipo di schema crittografico utilizzato.
Il ransomware è scritto in C++ e guardando la funzione WinMain con IDA si può osservare che le stringhe risultano offuscate.
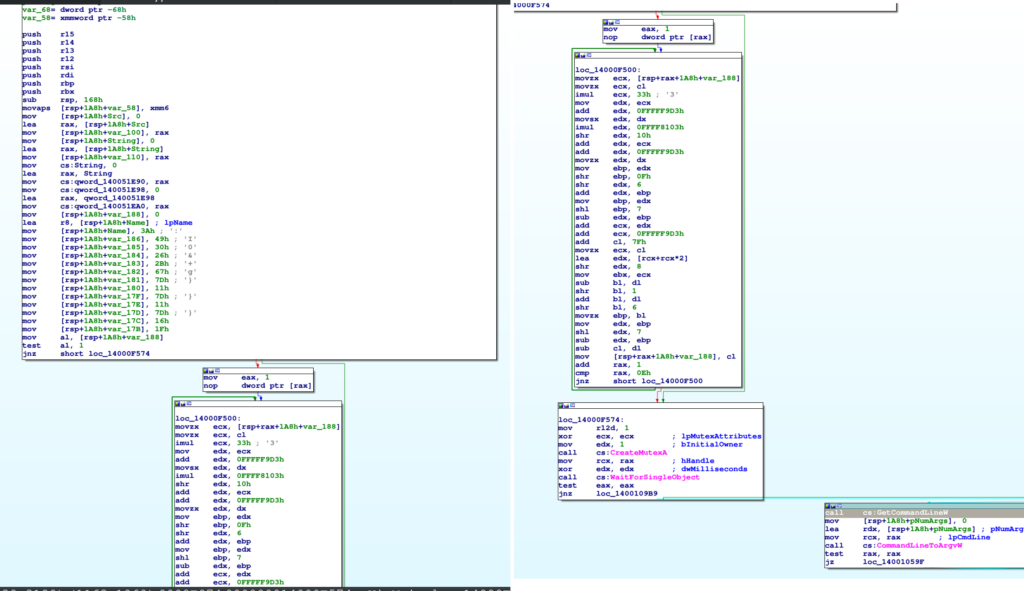
Dal frammento di codice qui sopra (l’inizio della funzione WinMain) si nota che la stringa che funge da nome del mutex è creata in un’area apposita nello stack e decodificata dal codice successivo. Questa forma di offuscazione è probabilmente realizzata con una macro (o un template) poichè ha sempre la stessa forma:
mov [rsp/rbp + offset], 0 ;Flag stringa cifrata (bit0: 0 = cifrata, 1 = non cifrata )
mov [rsp/rbp + offset + 1], ch0 ;Carattere cifrato stringa
mov [rsp/rbp + offset + 2], ch1 ;Carattere cifrato stringa
...
mov [rsp/rbp + offset + k+1], chk ;Carattere cifrato stringa
mov[zx] reg, [rsp/rbp + offset] ;Controlla se la stringa è cifrata
test reg, 1
jnz _after_decryption
; -- decription code --
_after_decryption:Estrazione delle stringhe
Le istruzioni di decodifica della stringa sono numerose e generate appositamente per rendere l’automazione complicata. Probabilmente si tratta di una serie di template/casi di codice C++ scelti in base al valore ed alla posizione dei caratteri della stringa e sarebbe possibile isolarli e scrivere un algoritmo di decifratura.
Un altro modo di decifrare le stringhe però è quello di usare un framework di esecuzione concolica (o meglio concreta in questo caso). Ci sono vari framework per l’esecuzione concolica/simbolica: uno particolarmente semplice da usare è Triton. L’idea è quella di identificare il codice che genera le stringhe codificate in memoria, eseguirlo concolicamente e leggere le stringhe decifrate. A tal fine è necessario:
- Identificare il codice che genera le stringhe e recuperare le informazioni necessarie (offset della stringa nello stack, lunghezza, virtual address dell’istruzioni prima e dopo il codice di decifratura).
- Eseguire il codice di decifratura.
Un fatto molto utile per la ricerca delle stringhe cifrate è che il codice che le genera nello stack è sempre alla fine di un Basic Block (abbreviato in BB, una sequenza continua di istruzioni senza salti). Questo è vero per via della natura della funzione di decifratura che fa un controllo del flag della stringa appena generata e quindi, in quanto questo contiene un salto, termina il BB corrente.
E’ possibile quindi cercare i BB che terminano con la sequenza di istruzioni:
mov[zx] al/cl/dl/eax, [rsp/rbp+x] / test al/cl/dl/eax, 1 / jnz y.
Tecnicamente, il template di istruzioni da cercare è più ristretto, nel senso che il registro usato nella load deve essere lo stesso di quello usato dall’istruzione test ma anche così facendo non si hanno falsi positivi.
Altro fatto degno di nota è che la load usata prima dell’istruzione test legge il flag della stringa: questo flag si trova esattamente prima dell’inizio della stringa stessa, per cui da quella load è possibile determinare l’offset nello stack della stringa.
Infine, il target dell’istruzione jnz ci fornisce il Virtual Address della prima istruzione dopo il codice di decodifica mentre l’istruzione successiva (il fall-through) è l’inizio di tale codice. Con queste informazione è semplice trovare ed isolare le stringhe ed il loro codice.
Il codice Python che segue, fa uso della classe BasicBlock che compare spesso negli script che usiamo per l’automatismo della deoffuscazione di codice macchina (es: nel malware Strela). Questa classe è costruita sulla libreria iced-x86 e permette di costruire un CFG a partire da un VA ed un file PE.
Il codice sotto riportato è usato per ottenere una serie di oggetti EncodedString che rappresentano le stringhe codificate all’interno del ransomware:
"""
Check if the BasicBlock bb contains an encoded string.
The code handling the string is necessarily at the end of the BB if present.
"""
def is_encoded_string(bb: BasicBlock, pe: PE) -> typing.Union[EncodedString, False]:
"""
Check if an instruction has the form <mnemonic> <reg>, ...
"""
def is_op_reg(i, mnemonic, dst_reg):
return i.mnemonic == mnemonic and i.op0_kind == ix86.OpKind.REGISTER and (i.op0_register in dst_reg if isinstance(dst_reg, list) else (i.op0_register == dst_reg))
"""
Get the displacemente from RSP/RBP in loads from memory (e.g.: in mov eax, [rbp+241] this function returns 241). The the instruction is not a load
from rbp/rsp the returned value is None
"""
def get_rsp_disp(i):
return i.memory_displacement if i.op1_kind == ix86.OpKind.MEMORY and i.memory_base in [ix86.Register.RSP, ix86.Register.RBP] and i.memory_index == ix86.Register.NONE else None
"""
Check if the source of the instruction is an immediate
"""
def is_src_imm(i, imm):
return i.op1_kind == ix86.OpKind.IMMEDIATE8 and i.immediate(1) == imm
"""
Get the displacement from RBP/RSP and the value of a store. (e.g. in mov [rbp+241], 56 this functions return (241, 56)).
If the instruction is not a store to RBP/RSP, (None, None is returned)
"""
def get_mov_rsp_off_imm(i):
return (i.memory_displacement, i.immediate(1)) if (
i.mnemonic == ix86.Mnemonic.MOV and i.op0_kind == ix86.OpKind.MEMORY and i.memory_base in [ix86.Register.RSP, ix86.Register.RBP] and i.memory_index == ix86.Register.NONE
and i.op1_kind == ix86.OpKind.IMMEDIATE8) else (None, None)
"""
Step 1. Check if the BB end with three specific instruction.
"""
#Three instructions are the "signature" of string decoding code, one if for storing the flag and one is for storing at least one char of the string
if len(bb.instructions) < 5:
return False
#
#Last instructions:
#
# must be mov al, [rsp/rbp+x] or mov eax, [rsp/rbp+x]
# set string_start_disp to be the offset in the stack (from rbp/rsp, it doesn't matter) of the string's flag (which is just before the beginning of the string)
if (not (
is_op_reg(bb.instructions[-3], ix86.Mnemonic.MOV, [ix86.Register.AL, ix86.Register.DL, ix86.Register.CL])
or
is_op_reg(bb.instructions[-3], ix86.Mnemonic.MOVZX, ix86.Register.EAX)
)
or
(string_start_disp := get_rsp_disp(bb.instructions[-3])) is None):
return False
# test al, 1; jnz
if (not is_op_reg(bb.instructions[-2], ix86.Mnemonic.TEST, [ix86.Register.AL, ix86.Register.DL, ix86.Register.CL])
or not is_src_imm(bb.instructions[-2], 1)):
return False
#jnz
if bb.instructions[-1].mnemonic != ix86.Mnemonic.JNE:
return False
#This is the VA of the first instruction after the code that decode the string. It's the target of the jnz instruction (that conveniently)
post_decoding_ip = bb.instructions[-1].near_branch_target
#This is the VA of the first instruction of the decoding code
decoding_ip = bb.instructions[-3].ip
#This is the VA of the jnz instruction itself (useful to patch it)
patch_jump = bb.instructions[-1].ip
#The bytes of the encoded string
encoded_string = []
#The offset from RSP/RBP of the first byte of the string (this is just string_start_disp + 1 anyway)
first_char_disp = 0xffffffff
#The address of the immediate bytes of the stores that generate the encoded string in the stack (useful to patch them)
patch_chars = []
#
first_char_ip = None
#Scan each instruction in the BB in reverse order (skipping the last three)
for i in range(len(bb.instructions)-4, -1, -1):
ins = bb.instructions[i]
#If this is a store to RSP/RBP of a byte, get the offset and the byte
disp, imm = get_mov_rsp_off_imm(ins)
#Not a store, ignore this instruction. The compiler probably reordered it
if disp is None:
continue
#If this is the store that stores the flag, we have reached back far enough, return an EncodedString
if disp == string_start_disp:
#Just some sanity check
if imm != 0 or first_char_ip is None:
return False
#We are done, return an object with all the info
return EncodedString(decoding_ip, post_decoding_ip, bytearray(encoded_string), first_char_disp, string_start_disp, patch_chars, patch_jump, first_char_ip, pe)
#This could be a store for an encoded char then
else:
#Update the minimum displacement seen so far (and the VA of the store)
if disp < first_char_disp:
first_char_disp = min(first_char_disp, disp)
first_char_ip = ins.ip
#Add the encoded char at the beginning (we are scanning backwards)
encoded_string.insert(0, imm)
#We need the offset of the immediate byte in the store, is there a better method than this?
decoder = ix86.Decoder(64, bytes(), ip=ins.ip)
offsets = decoder.get_constant_offsets(ins)
patch_chars.insert(0, ins.ip+offsets.immediate_offset)
#Something went wrong
return False
"""
Given the first BB of a function, find all the encoded strings
"""
def find_encoded_strings(bb: BasicBlock, pe: PE) -> typing.Union[EncodedString, False]:
"""
Each BB is labelled with 1 once visited to avoid infinite recursion
"""
#Is this BB already visited?
if bb.label != 0:
return []
#Mark this BB as visited
bb.set_label(1)
#Encoded strings found
strings = []
#If this BB decodes a string, add it to the list
res = is_encoded_string(bb, pe)
if res:
strings.append(res)
#Recurse to the next BB
if bb.next:
strings += find_encoded_strings(bb.next, pe)
#Recurse to the branch BB
if bb.branch:
strings += find_encoded_strings(bb.branch, pe)
return strings Il codice ricalca le considerazioni fatte precedentemente: cerca i BB con le tre istruzioni firma e poi, a ritroso, cerca le store di immediati di 8-bit. Ai fini di patchare il PE del ransomware (affinchè contenga i byte non cifrati e sia eliminato il salto condizionale sul flag della stringa) sono memorizzati una serie di Virtual Address (VA) ed offset aggiuntivi.
Decodifica delle stringhe con Triton
Una volta ottenuta la lista di oggetti EncodedString è necessario decodificare le stringhe. Tra le informazioni ottenute c’è il VA della prima istruzione del codice di decodifica ed il VA della prima istruzione dopo questo. E’ quindi possibile simulare l’esecuzione con Triton a partire dal primo VA fino al secondo. E’ necessario impostare solo il valore dei registri rbp, rsp e rip. Impostando rbp ed rsp a 0, gli offset ottenuti nella fase di ricerca (e che sono relativi a rbp/rsp) potranno essere usati come indirizzi assoluti dove scrivere la stringa codifica (con setConcreteMemoryAreaValue) e leggere quella decodifica (con getConcreteMemoryAreaValue) a fine esecuzione.
Triton è particolarmente comodo da usare per l’esecuzione concolica perchè permette di specificare via via le istruzioni da eseguire a partire dai byte del codice macchina.
Il codice che decodifica la stringa è il seguente:
"""
Get the decoded string
The result is cached
"""
@property
def decoded(self) -> bytearray:
if self._decoded is None:
#Create a Triton context
ctx = TritonContext()
#For the X86-64 architecture
ctx.setArchitecture(ARCH.X86_64)
#Since this is a simulation we can make RBP/RSP point to zero so we can use the offset given directly without adding any base
ctx.setConcreteRegisterValue(ctx.registers.rsp, 0)
ctx.setConcreteRegisterValue(ctx.registers.rbp, 0)
#We start the execution from the decoding code
ctx.setConcreteRegisterValue(ctx.registers.rip, self._decoding_start_ip)
#Set the encoded string in memory
ctx.setConcreteMemoryAreaValue(self._first_char_disp, self._encoded_string)
#Set the flag also (though it's not read)
ctx.setConcreteMemoryAreaValue(self._flag_disp, bytes([0]))
#We continue execution until we reach the first instruction after the decoding code
while ctx.getConcreteRegisterValue(ctx.registers.rip) != self._post_decoding_ip:
#Get current RIP value
ip = ctx.getConcreteRegisterValue(ctx.registers.rip)
#Make a new instruction (Triton will execute a single instruction regardless of how many bytes are set with setOpcode, nice!)
cur_ins = Instruction()
cur_ins.setAddress(ip)
cur_ins.setOpcode(self._pe.data[self._pe.at_va(ip)][:16])
#Single step of concolic execution!
ctx.processing(cur_ins)
#OK, time to read back from what was once the encoded string
self._decoded = ctx.getConcreteMemoryAreaValue(self._first_char_disp, len(self._encoded_string))
return self._decodedE’ bene dire che non tutte le stringhe codificate sono rilevate dal codice mostrato. Alcune stringhe hanno una funzione apposita per la loro decodifica (evidentemente il compilatore non ha fatto l’inlining per qualche ragione) ed alcune hanno un template di istruzioni leggermente diverso. Per questo motivo nello script sotto sono forniti anche le funzioni single_function, single_block ed emulate per l’inserimento manuale dei parametri di decodifica. Il codice completo si trova qui ed è fornito a puro scopo informativo (come al solito, contiene percorsi hardcoded) ma può essere facilmente modificato per una decodifica più completa.
Il PE patchato che risulta dallo script e lo script IDC generato permettono di vedere le stringhe in chiaro nel database IDA.
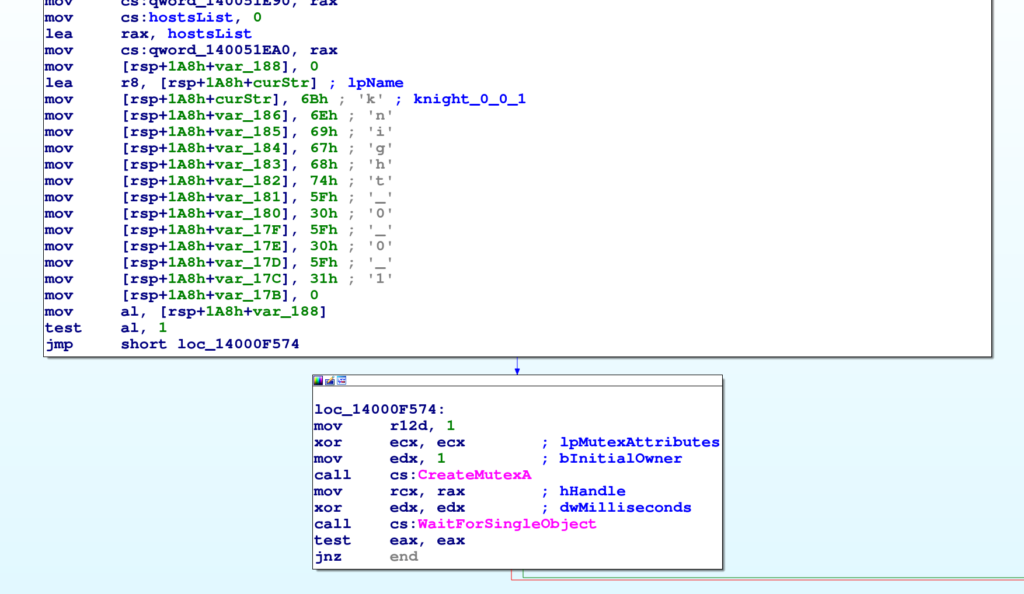
L’immagine sopra illustra lo stesso codice mostrato all’inizio di questa sezione dove questa volta però il nome del mutex è in chiaro. E’ interessante notare come il ransomware crei un mutex di nome “knight_0_0_1“: questa tecnica è infatti facilmente rilevabile da un EDR e rende il malware facilmente identificabile. Evidentemente l’assunzione degli autori è che il ransomware sia eseguito in un ambiente privo di sistemi di risposta, magari perchè assenti o disabilitati.
Le modalità di esecuzione del ransomware
Dettagliare con delle immagini i particolari del ransomware è laborioso per via dell’estensione del codice rilevante. In breve, Knight ha 5 diverse modalità di ricerca dei file da cifrare. Queste modalità sono impostate da linea di comando come prima azione dopo la creazione del mutex per l’esecuzione esclusiva e terminano al nodo che abbiamo etichettato check_language.
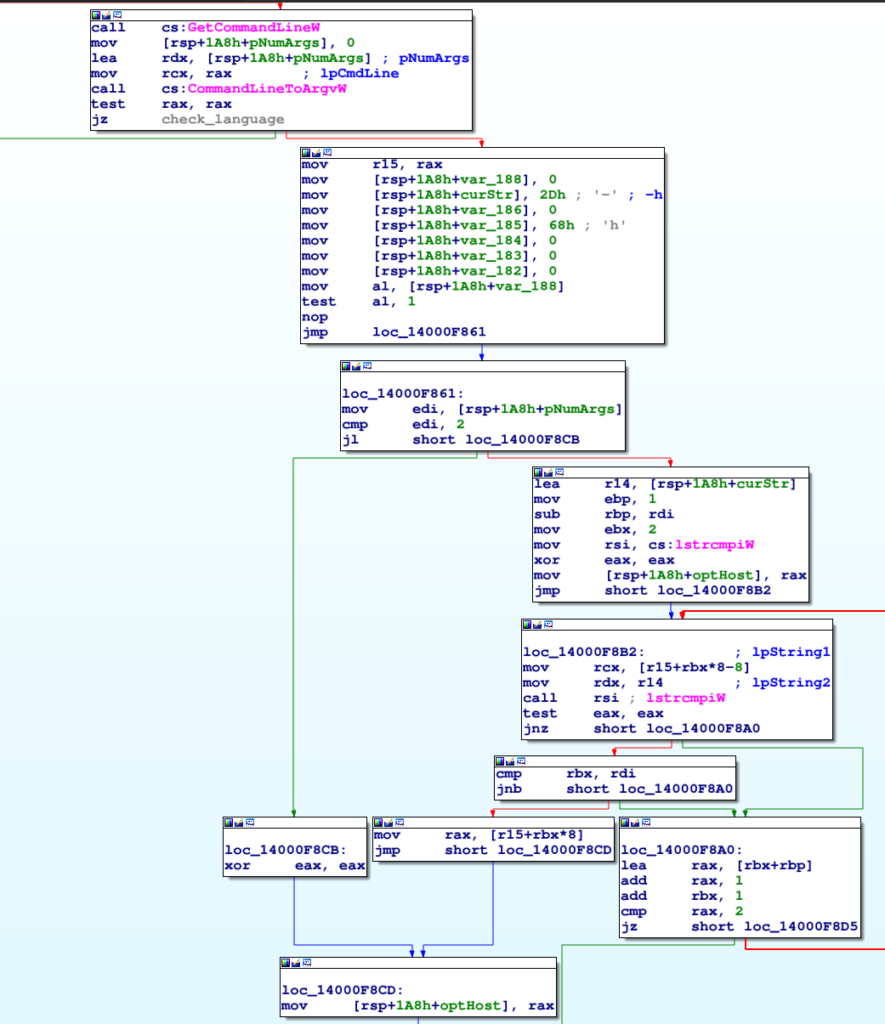
Leggendo il codice è possibile creare la seguente tabella delle opzioni da riga di comando di Knight e la relativa modalità di ricerca dei file.
| Opzione | Modalità | Valore numerico della modalità | Descrizione |
| -h <path> | Host | 0x0e | Legge da <path> una lista di nomi host (uno per riga) di cui enumerare le share. I file da cifrare sono presi da queste share. Ha la precedenza su -m. |
| -p <path> | Path | 0x0d | Legge da <path> una lista di percorsi locali (uno per riga). I file da cifrare sono presi da questi percorsi. Ha la precedenza su -m. |
| -m local | Local | 0x0b | Enumera solo i dischi locali (e cifra i file nei dischi trovati). |
| -m net | Net | 0x0c | Enumera solo gli host in rete locale (vedremo come) e per ogni host enumera le share. I file da cifrare sono presi da queste share. |
| -log enabled | – | – | Crea un file di log KNIGHT_LOG.txt nella stessa cartella del ransomware. |
| <nessuno> | Default | 0x0a | Modalità di default. Equivale a Local più Net. |
Il controllo della lingua
Prima di avviare le operazioni di ricerca dei file da cifrare il ransomware controlla la lingua della macchina della vittima tramite le API GetSystemDefaultUILanguage e GetUserDefaultUILanguage.
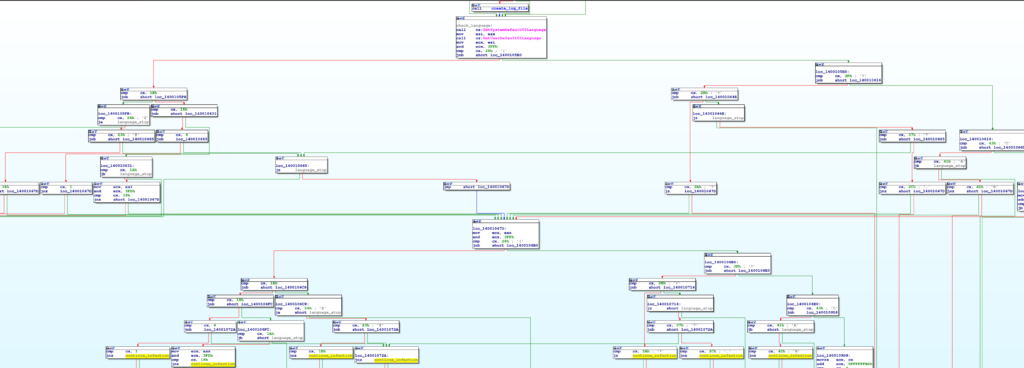
Il codice del ransomware controlla il LCID tramite una serie di blocchi if che risultano nel codice macchina sopra che è piututtosto frammentato. Per fortuna possiamo sempre usare Triton per verificare quale degli LCID da 0x0 a 0x400 (escluso) risultano in uno stop del ransomware:
def language(start, end1, end2, lcid):
ctx = TritonContext()
ctx.setArchitecture(ARCH.X86_64)
ctx.setConcreteRegisterValue(ctx.registers.rcx, lcid)
ctx.setConcreteRegisterValue(ctx.registers.rip, start)
while ctx.getConcreteRegisterValue(ctx.registers.rip) not in [end1, end2]:
cur_ins = Instruction()
ip = ctx.getConcreteRegisterValue(ctx.registers.rip)
cur_ins.setAddress(ip)
cur_ins.setOpcode(sample.data[sample.at_va(ip)][:16])
ctx.processing(cur_ins)
return ctx.getConcreteRegisterValue(ctx.registers.rip) == end1
for x in range(0, 0x400):
if language(0x1400105b5, 0x140010730, 0x1400109e8, x):
print(hex(x))Le lingue per cui il ransomware blocca la sua azione sono quelle dei paesi appartenenti al blocco CIS, dei paesi con lingua araba e cinese (nello specifico i seguenti language id: 0x1, 0x4, 0x18, 0x19, 0x1a, 0x1e, 0x23, 0x25, 0x26, 0x27, 0x28, 0x29, 0x2b, 0x2c, 0x37, 0x3f, 0x40, 0x42, 0x43, 0x44).
Preparazione all’infezione
Prima di avviare la fase di ricerca dei file da cifrare il ransomware compie alcune operazioni preliminari:
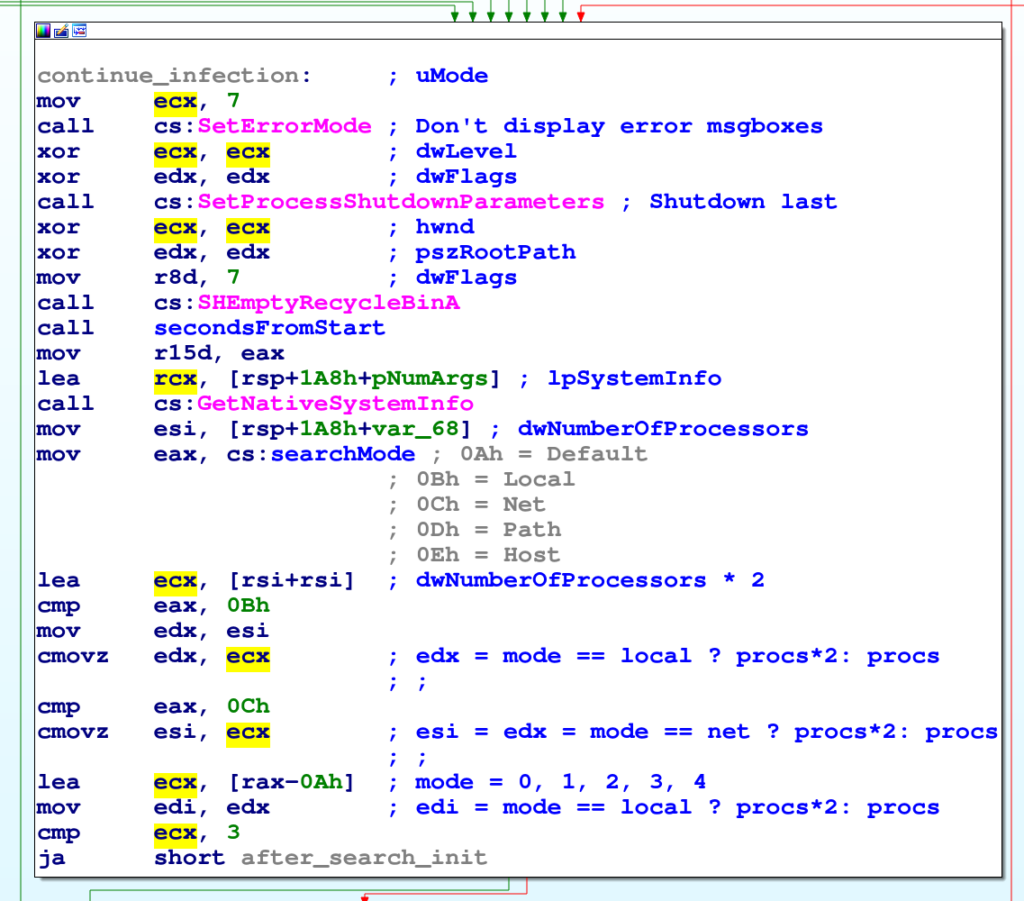
- Disabilita la visualizzazione di messaggi di errori in caso di eccezioni non gestite.
- Si imposta come uno degli ultimi processi da terminare in caso di spegnimento della macchina.
- Svuota il cestino.
- Calcola il numero di thread per le operazioni di ricerca.
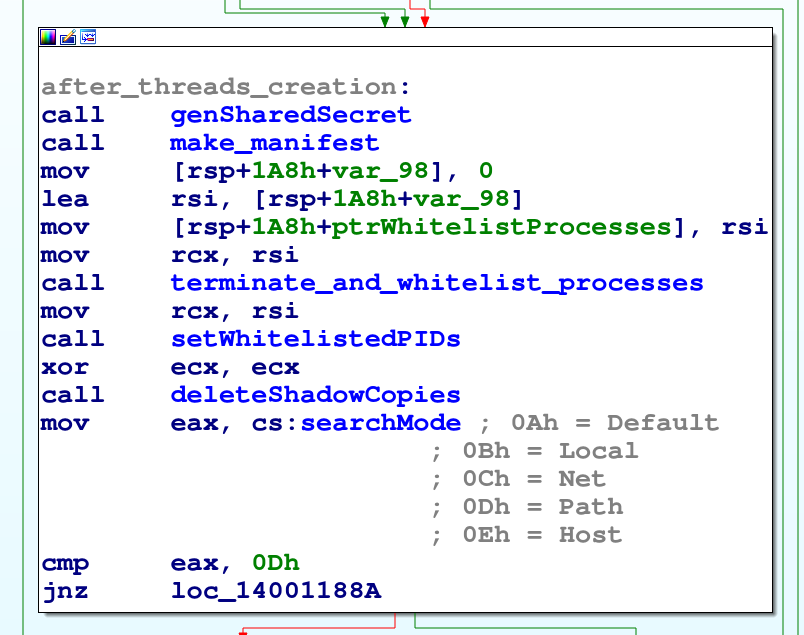
Prima di parlare dei thread usati da Knight, terminiamo la lista di operazioni preliminari. Poco dopo infatti troviamo il seguente blocco di codice:
Lo schema crittografico di Knight, almeno nella versione per Windows, fa uso di X25519 e HC-256. Il primo è usato per implementare lo scambio di chiavi e HC-256 è uno stream chiper molto veloce. Lo schema segue la classica costruzione in cui un protocollo Diffie-Hellman è usato per generare un segreto comune da cui derivare le chiavi per i singoli file ed un cifrario simmetrico è usato per la cifratura effettiva dei file.
La funzione genSharedSecret è mostrata qui di seguito. Risulta evidente che siamo in presenza di X25519. Il codice segue infatti l’uso standard di X25519 per generare un segreto.
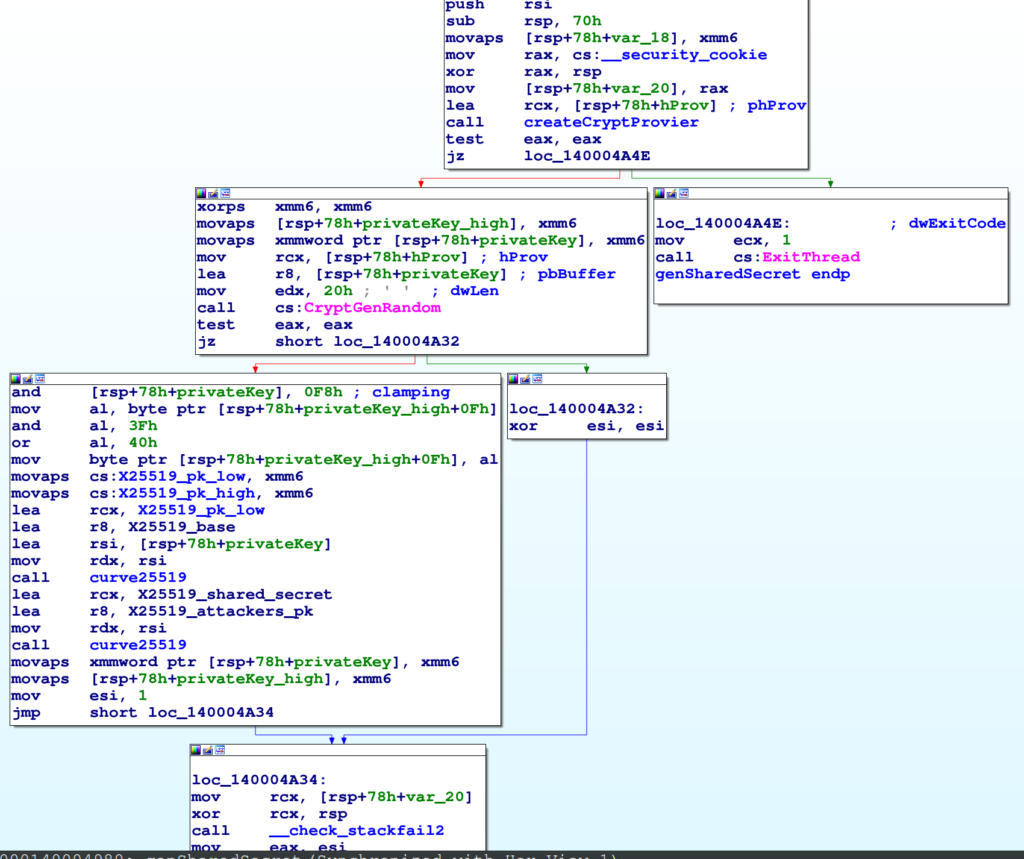
Vedremo più avanti il formato dei file cifrati.
Oltre alla generazione di key material per le operazioni crittografiche, tra le operazioni preliminari vi è quella di generare il testo del file manifest. Il codice si trova nella funzione make_manifest ed è piuttosto intuitivo. I parametri del manifesto (tipo indirizzo tor, del wallet, build id) sono variabili globali codificate in esadecimale.
Terminazione e whitelist dei processi
Un’altra operazione preliminare di Knight è la terminazione della seguente lista di processi:
agntsvc.exe, dbsnmp.exe, dbeng50.exe, encsvc.exe, excel.exe, firefox.exe, isqlplussvc.exe, msaccess.exe, mspub.exe, mydesktopqos.exe, mydesktopservice.exe, notepad.exe, ocautoupds.exe, ocomm.exe, ocssd.exe, oracle.exe, onenote.exe, outlook.exe, powerpnt.exe, sqbcoreservice.exe, sql.exe, steam.exe, synctime.exe, tbirdconfig.exe, thebat.exe, thunderbird.exe, visio.exe, winword.exe, wordpad.exe, xfssvccon.exe.
Lo scopo è quello di evitare che questi programmi blocchino la scrittura dei file. E’ interessante notare che la lista contiene programmi ad uso desktop, il che non fa che confermare che questo campione sia stato creato per colpire utenti domestici (la lista è probabilmente modificabile durante il build del payload).
I processi che seguono sono invece aggiunti ad una whitelist: questi non saranno terminati neanche qualora impediscano la scrittura di file da cifrare: explorer.exe, vmcompute.exe, vmms.exe, vmwp.exe, svchost.exe, TeamViewer.exe. I processi in whitelist sono salvati in una variabile globale da setWhitelistedPIDs in forma di lista doppiamente concatenata.
Anche qui è interessante notare come siano presenti i servizi guest di alcuni hypervisor e di Team Viewer: questo è ciò che ci si aspetterebbe da un sample creato per ambienti enterprise.
Infine, le Shadow Copy dei volumi sono cancellate, tramite WMI, per evitare il recupero dei file cifrati.
I thread e la ricerca dei file da cifrare
Knight usa un pool di thread per eseguire le seguenti operazioni:
- Ricerca dei file da cifrare all’interno di percorsi (locali o di rete).
- Ricerca di percorsi di rete in un dato host.
- Port scanning degli host in rete locale.
- Cifratura dei file.
La comunicazione tra thread avviene tramite una serie di oggetti globali dotati di meccanismi di sincronizzazione (sezioni critiche ed eventi) ed di liste doppiamente concatenate per lo scambio di informazioni (dette pool).
I thread di ricerca file leggono dal pool di ricerca i percorsi (locali o di rete) ed usano le classiche API FindFirstFileEx e similari per cercare i file, alcuni dei quali, come vedremo, verranno esclusi dalla cifratura. I thread di port scanning verificano se un dato nome host ha il servizio SMB raggiungibile provando a stabilire una connessione sulla porta 445. I thread di ricerca dei percorsi di rete enumerano le share (cartelle condivise) di tipo disco di un dato host (escludendo $ADMIN) e aggiungono queste al pool di ricerca.
In base alla modalità scelta, WinMain popola il pool di ricerca con le root dei dischi locali o con una serie di percorsi passati con il parametro -p. Sempre in base alla modalità scelta, viene aggiunto un insieme di nomi host al pool degli host di cui enumerare le share oppure viene fatta una scansione della rete locale.
L’enumerazione dei dischi locali non presenta caratteristiche degne di nota. Ci focalizzeremo quindi solo sulla ricerca degli host in rete locale e l’enumerazione delle share.
La funzione che enumera gli host in rete locale è enum_local_hosts_and_scan. Oltre ad ottenere un puntatore a ConnectEx per la “scansione” sulla porta 445 degli host trovati, questa funzione legge la tabella ARP per determinare gli host con cui la macchina vittima ha comunicato.

Ogni singola entry è convertita in un IP in formato stringa e solo quelli il cui prefisso è 192.168. o 10. o 169. o 172. verranno considerati.
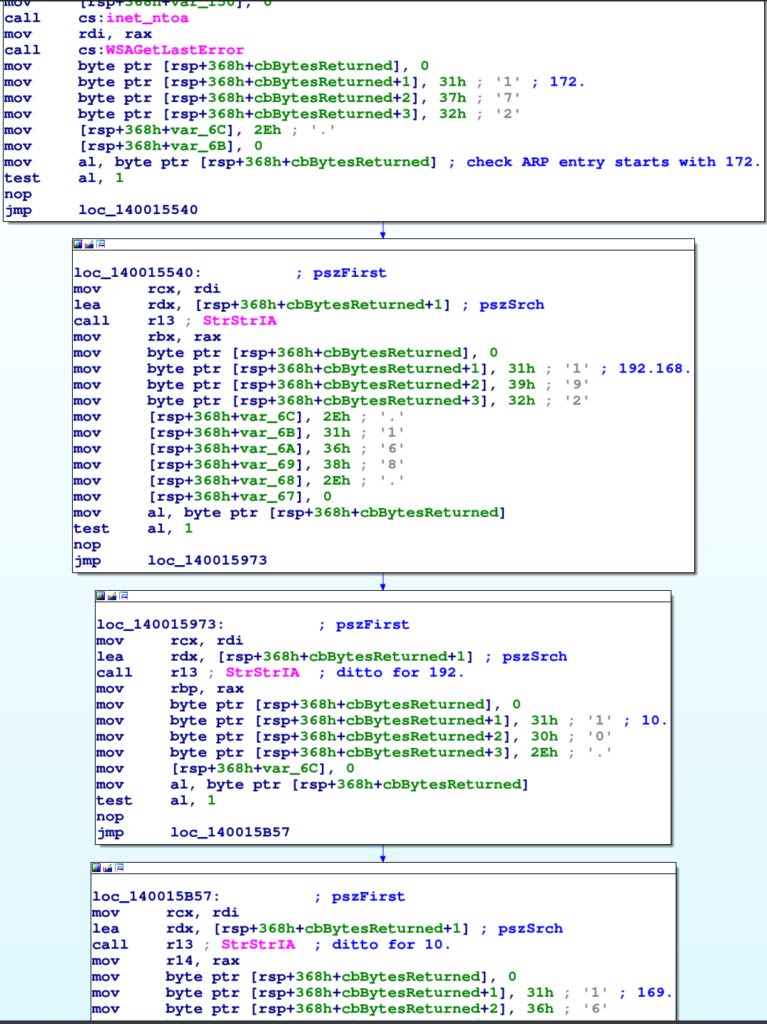
I range controllati da Knight non sono del tutto corretti. 192.168.0.0/16 è un range privato così come 10.0.0.0/8 ma 169.0.0.0/8 e 172.0.0.0/8 non lo sono. Il primo è infatti probabilmente usato per gli host con IP privato automatico, che però ricadono nel range 169.254.0.0/16 mentre il secondo è usato per gli host nel range privato 172.16.0.0/12.
È quindi teoricamente possibile che una vittima infetti anche host pubblici attraverso internet (in realtà è molto improbabile che questi host abbiamo share pubblicamente accessibili).
L’enumerazione delle share di un host è fatta in enum_shares ed usa semplicemente l’API NetShareEnum e filtra le share non di tipo disco o di nome $ADMIN (che rappresenta il percorso dell’installazione di Windows nella macchina e quindi non di interesse del ransomware).
Nel pool di ricerca sono riportati i percorsi in cui cercare i file da cifrare. Più thread leggono da questo pool e cercano file cifrabili. Il campione analizzato escludeva le seguenti cartelle ed i seguenti tipi/nomi file:
| Cartelle escluse | windows, thumb, appdata, application data, google, mozilla, program files, program files (x86), programdata, system volume information, tor browser, windows.old, intel, msocache, perflogs, x64dbg, public, all users, default, windows nt, msbuild, microsoft, system volume information, perflog, google, application data, microsoft.net, microsoft shared, internet explorer, common files, opera, windows journal, windows defender, windowsapp, windowspowershell, usoshared, windows security, windows photo viewer |
| File esclusi | .cpOBFW(L, .deskthemepack, .diagcab, .diagcfg, .diagpkg, .dlOBFW(L, .icOBFW(L, .icns, .msstyles, .nomedia, .spOBFW(L, .theme, .themepack, .lock, .iso, .woff, .part, .sfcache, .winmd, How To Restore Your Files.txt, KNIGHT_LOG.txt, .woff, $recycle.bin, $recycle.bin, config.msi, $windows.~bt, $windows.~ws, |
Notare come siano esclusi anche file e programmi utili per il debug del ransomware da parte degli autori.
I file trovati sono aggiunti in un apposito pool letto dai thread di cifratura.
Cifratura dei file
I file sono cifrati dalla funzione encrypt_file. Lo schema crittografico ed il formato utilizzati sono relativamente semplici da analizzare rispetto ad altri ransomware e, in particolare, tutte le operazioni di preparazione alla cifratura sono effettuate all’inizio della funzione.
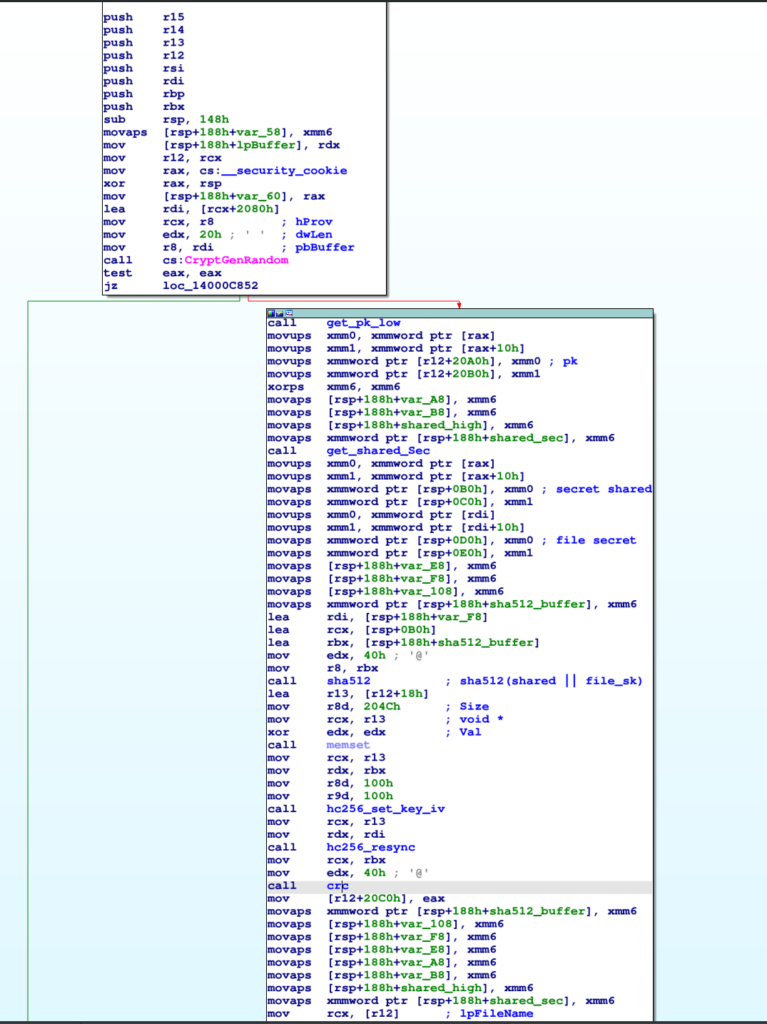
Nell’immagine sopra le primitive crittografiche sono già state identificate.
Si nota infatti che l’IV generato per file con CryptGenRandom è concatenato (nello stack) al segreto generato all’avvio del ransomware e di questo BLOB di 256+256 bit è fatto lo SHA-512. Non è chiaro il motivo di questa operazione: forse come protezione aggiuntiva contro attacchi di crittoanalisi contro HC-256? Il risultato dell’hash è usato come chiave di HC-256. I file saranno cifrati, chunk per chunk, con questo cifrario:
IV <-R 32B //32B random
KIV = SHA512(secret || IV)
HC256-SetKeyIV(KIV) //Init HC-256 cipherRimane da determinare il formato dei file cifrati e quali parti sono cifrate. Anche Knight, come ogni ransomware professionale, cifra solo alcune parti dei file. Se così non fosse le operazioni di cifratura sarebbero molto lunghe con conseguente rischio di rilevamento o interruzione.
La funzione encrypt_file è piuttosto semplice da seguire anche se è un po’ laboriosa.
Il suo funzionamento si può riassumere come:
- Prova ad aprire il file in lettura-scrittura con
CreateFileW. - Se fallisce perchè in uso:
- 1. Termina il processo che sta bloccando il file (ottenuto tramite
RmStartSession& C., si vedaterminate_processe questo) se non presente nella whitelist menzionata precedentemente.
- 1. Termina il processo che sta bloccando il file (ottenuto tramite
- Prova a riaprire il file, se fallisce ritorna dalla funzione.
- Ottiene la dimensione del file, se fallisce o questa è zero, ritorna dalla funzione.
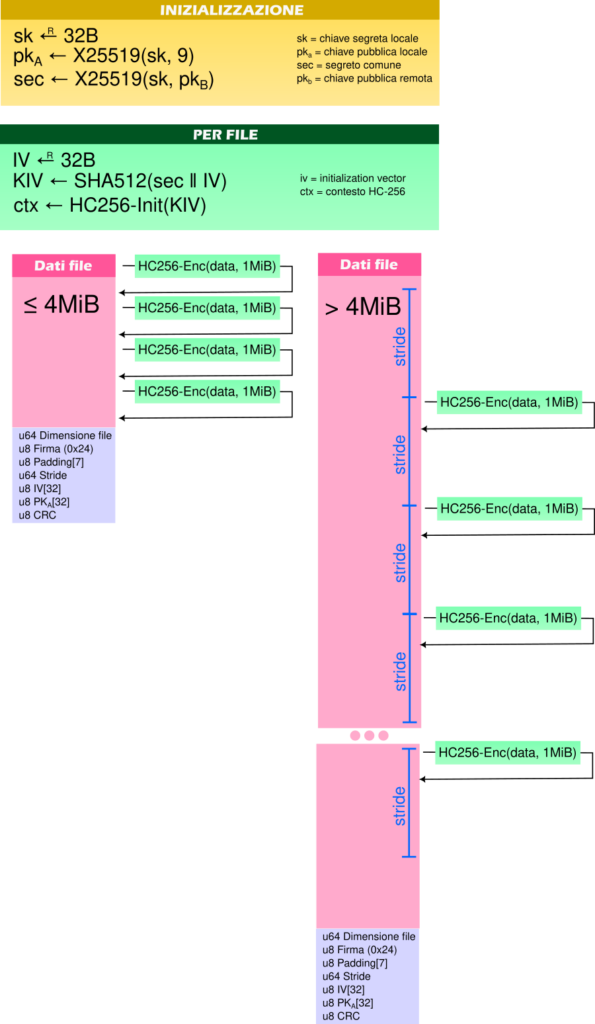
- In base alla dimensione, è impostato il parametro
stride, ovvero ogni quanti byte cifrare un blocco da 1MiB (si veda tabella sotto). - In fondo al file sono scritti 0x68 byte a partire dall’offset 0x2068 della struttura indicata prima. Queste informazioni consentono di decifrare il file.
- I file:
- Sotto i 4MiB sono letti interamente e cifrati in-place a blocchi di 1MiB.
- Sopra i 4MiB sono cifrati in-place leggendo 1MiB ogni
stridebyte a partire dastride + 0x100000.
Tabella degli stride in base alla dimensione del file
| Dimensione | Stride |
| (0, 4MiB] | 0B (tutto il file è cifrato) |
| (4MiB, 8MiB] | 512KiB |
| (8MiB, 32MiB] | 1MiB |
| (32MiB, 128MiB] | 2MiB |
| (128MiB, 512MiB] | 4MiB |
| (512MiB, 2GiB] | 8MiB |
| (2GiB, 8GiB] | 16MiB |
| (8GiB, 32GiB] | 32MiB |
| (32GiB, 128GiB] | 64MiB |
| (128GiB, 512GiB] | 128MiB |
| (512GiB, 2TiB] | 256MiB |
| (2TiB, 8TiB] | 512MiB |
| (8TiB, +∞) | 1GiB |
Dalla tabella sopra non si nota che lo stride è sublineare nella dimensione del file (s = 0x80000 * 2^( floor( (log2(d)-21)/2 ) ), dove s è lo stride e d la dimensione del file, da cui:
s ~ 0x80000 * sqrt(d / 2^21))
per cui più i file sono grossi più sono impattati dal ransomware. Questo potrebbe essere un meccanismo per evitare che la cifratura di un grosso file, come una VM, risulti inutile perchè troppi pochi blocchi sono stati cifrati (come è successo per ESXiArgs).
Altro fatto interessante che si nota dalla tabella sopra è che Knight è stato pensato per file anche molto grandi. Almeno stando al codice, gli autori hanno determinato un valore dello stride per file fino a 8TiB.
Di seguito il riepilogo dello schema crittografico e del formato dei file:
Conclusioni
Dal punto di vista tecnico, Knight è un ransomware che segue i principi di progettazione standard per questo tipo di malware. Dall’analisi di questo campione sono comunque emerse interessanti caratteristiche tra cui:
- La campagna Knight che ha impattato l’Italia è stata diffusa via e-mail, fatto insolito per un ransomware che è generalmente l’ultimo stadio di un attacco che parte con altri tipi di malware. Altri elementi (come l’elenco dei programmi da terminare) confermano che la campagna sia stata mirata verso utenti domestici.
- Allo scopo di evitare sistemi EDR il ransomware è fornito con il packer IDAT Loader che è un packer molto recente (Luglio 2023) e piuttosto laborioso da analizzare.
- Il ransomware ha la capacità di trovare altre macchine in rete e di cifrare anche i file condivisi.
- La funzionalità di ricerca delle macchine locali non è perfettamente implementata ed è teoricamente possibile (ma altamente improbabile) che il ransomware cifri i file di macchine pubbliche su internet.
- Il ransomware non attacca macchine Arabe, Cinesi e del blocco CIS.
- Il ransomware non cifra file di sistema o di applicazioni necessarie all’uso della macchina.
- La crittografia usata è semplice ma efficace.
- Knight è stato pensato per cifrare file anche molto grandi (8TiB e oltre) in modo efficiente, alterando blocchi da 1MiB l’uno ad una distanza dall’altro che dipende in modo sublineare dalla dimensione del file.