YAU – Parte 3 – Il packer
yau
Nell’articolo precedente abbiamo visto come analizzare i documenti malevoli utilizzati da Ursnif.
In particolare abbiamo mostrato come ottenere l’URL dal quale il dropper recupera il payload da eseguire.
Da più di un anno a questa parte il payload è una DLL eseguita con regsvr32.exe mentre in precedenza era un PE eseguibile (un .EXE).
Questo payload non contiene il codice del malware vero e proprio, trattasi infatti di un packer.
Il flusso di lavoro è sempre simile: in una fase iniziale viene decodificato il codice di estrazione del payload, nella fase successiva questo codice viene eseguito e il payload viene lanciato.
Questo ci permette di definire una strategia generale per l’approccio di reverse engineering da usare. In particolare, un breakpoint sulle funzioni di allocazione o protezione della memoria (NtAllocateVirtualMemory, VirtualAlloc, VirtualProtect e NtProtectVirtualMemory) risulta sempre efficace per portare l’analista al cuore del codice malevolo.
Compito non scontato data la mole di codice superfluo da cui è circondato.
Yet Another Ursnif

Questo è il terzo di una seria di articoli, tutti raggruppati qui.
Indice
Parte 1, Le e-mail e il documento Excel
Parte 2, Le macro
Parte 3, Il packer <–
Parte 4, Primo stadio e la sezione bss
Parte 5, Ancora il primo stadio e i “JJ chunk”
Parte 6, Il secondo stadio e i primi IoC
Parte 7, Il secondo stadio, seed, GUID e privilegi
Parte 8, Il secondo stadio, configurazione e download
Parte 9, Il secondo stadio, salvataggio dei moduli e persistenza
Parte 10, Rimozione di Ursnif
Parte 11, Il client, inizializzazione e configurazione
Parte 12, Il client, da powershell ad explorer.exe ai browser
Parte 13, Il client, comandi e trasmissione al C2
Parte 14, Il C2, panoramica
Parte 15, Il C2, i sorgenti e l’architettura
Parte 16, Il C2, vulnerabilità
Parte 17, OSINT e resoconto finale
L’entry-point
Analizzando la DLL scaricata dal dropper, la prima sfida per l’analista è quella di identificare il “vero” entry-point.
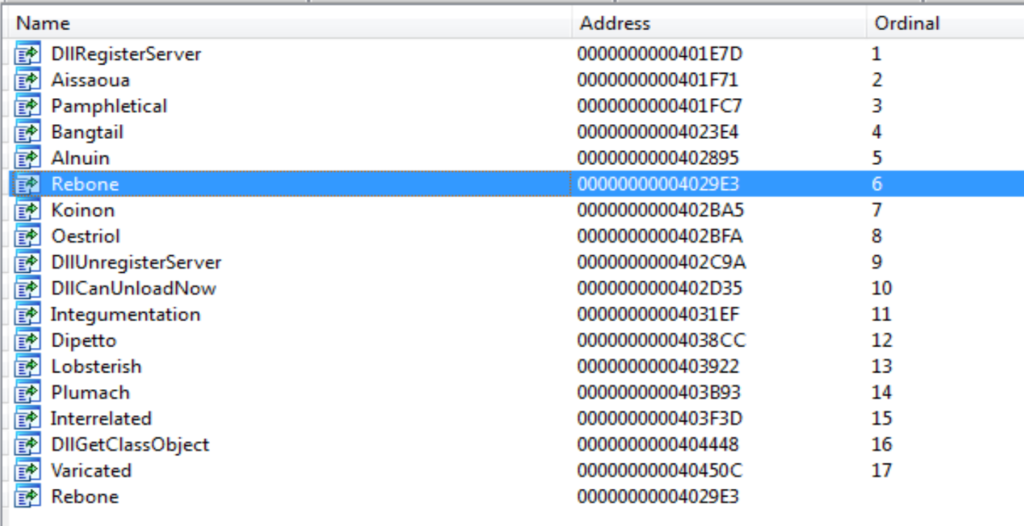
Ovviamente l’identificazione dell’entry-point PE non è problematica, in quanto indicato dall’header stesso.
Tuttavia l’entry-point PE è anche una funzione esportata dalla DLL, fatto che, in alcuni strumenti come IDA, lo fa apparire con un nome diverso da quello canonico (start in IDA).
Il compito difficile è capire qual’è l’entry-point “vero”, cioè quello dal quale si esegue il codice malevolo dell’eseguibile (e non del runtime o di altri componenti).
Oltre alle molte funzioni con nomi generati automaticamente, sono presenti le solite funzioni per la gestione dei server COM (che presentano il prefisso Dll nel nome).
E’ quindi necessario capire se il codice malevolo si trova partendo dal entry-point PE o da una di queste funzioni.
In tutti i sample analizzati, recenti o meno, l’esecuzione malevola inizia sempre dal entry-point PE (che in questo caso chiama DllMain).
Ma facciamo finta di non saperlo.
In questo sample l’entry-point PE è denominato Rebone. Prima di analizzarlo, dato che presenta molto codice superfluo, è utile avere una panoramica generale di cosa fanno le funzioni COM (in particolare DllRegisterServer), in modo da adottare un approccio breadth-first (piuttosto che depth-first).
Un’analista può facilmente disegnare in mente uno schema delle chiamate mentre esplora il codice, ma è più facile scriverlo, come abbiamo fatto qui sotto.
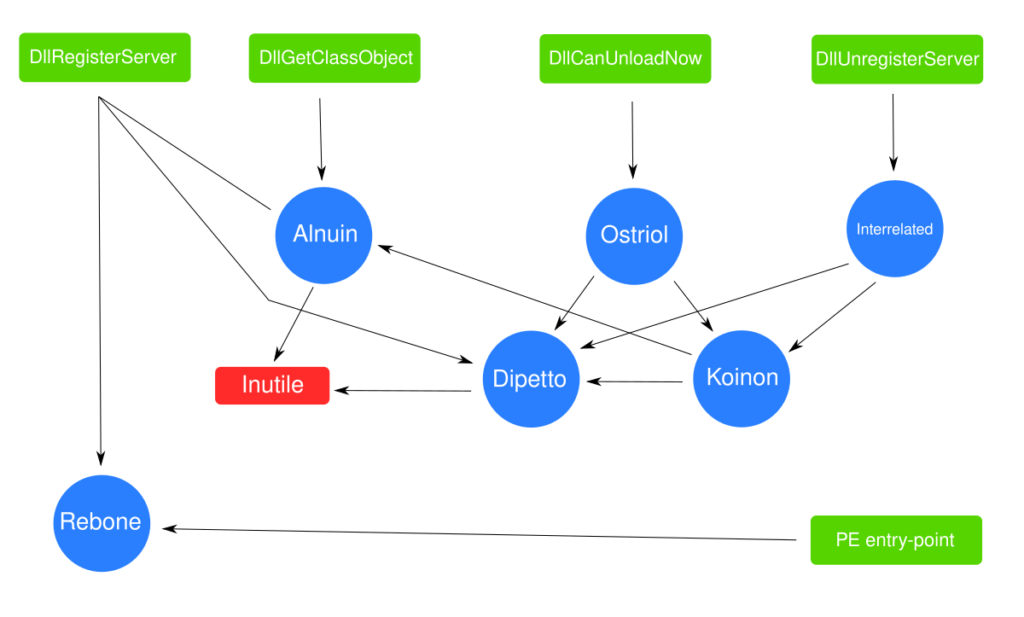
In questo schema non è importante sapere cosa “faccia” ogni funzione, ma solo quali sono le relazioni tra le chiamate.
In alcuni casi è possibile stabilire che una funzione non “fa niente di utile” (perchè non ha effetti collaterali).
Osservando il grafo sopra, si può vedere che molti percorsi portano a del codice inutile.
In particolare le funzioni COM, eccezion fatta per DllRegisterServer, non fanno niente di utile.DllRegisterServer chiama Rebone, ma questo è l’entry-point PE che comunque sempre eseguito.
Possiamo quindi ignorare le funzioni esportate.
Viene così stabilito che la funzione principale è proprio l’entry-point PE, ovvero Rebone.
Il codice malevolo
Il codice della funzione rebone è molto lungo e presenta chiamate alle altre funzioni esportate, nonché a varie API (ma sempre con parametri non validi).
Per l’analista è quindi evidente che si trova di fronte a del codice esca per distrarlo.
Come trovare il vero codice malevolo?
La prima volta è necessario navigare il codice, rinominando le funzioni inutili con un suffisso specifico (in modo da distinguerle) e avere un’idea generale del flusso di lavoro.
Abbiamo già fatto noi questa prima analisi per cui possiamo risparmiarla al lettore e quindi concludere che in generale il packer di Ursnif esegue i seguenti passi:
- Individuare l’indirizzo del codice di unpacking.
Questo è contenuto all’interno del packer, ad un indirizzo fisso ma variabile di sample in sample.

- Decodificare il codice di unpacking.
I sample recenti usanoVirtualProtectper rendere scrivibile l’area di memoria che contiene il codice di unpacking ed usano un semplice algoritmo di decodifica.
I sample del secondo quadrimestre del 2020 usavanoGlobalAllocper ottenere un buffer in cui veniva decodificato il codice di unpacking usando RC4.
I sample ancora più vecchi decodificavano il codice di unpacking inplace (dopo aver usatoVirtualProtect) con un algoritmo specifico. - Eseguire il codice di unpacking.
Viene sempre usato un salto indiretto, tipocall eax,push/retojmp eax.
Per individuare il codice malevolo è quindi utile vedere l’utilizzo delle funzioni di allocazione o protezione della memoria.
Se vediamo gli utilizzi di VirtualAlloc nei sample recenti, notiamo che è usato due volte. Di cui una in modo inutile.
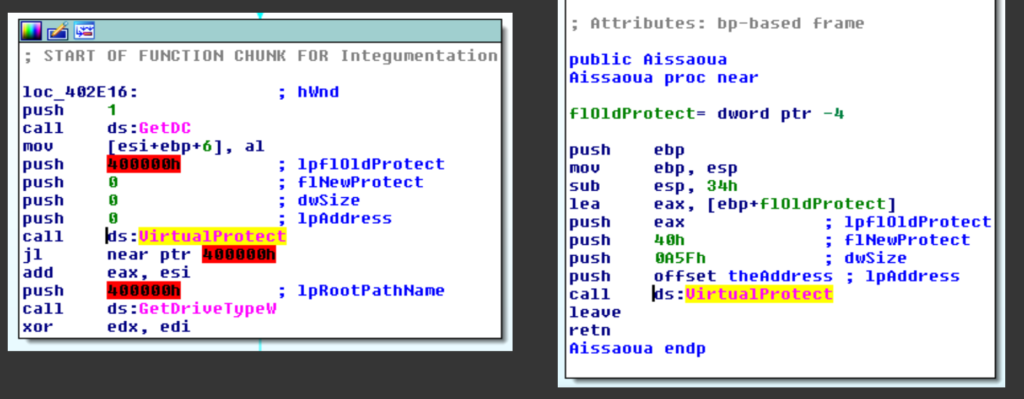
A questo punto è naturale chiedersi quale altro codice fa riferimento all’indirizzo theAddress mostrato nell’immagine sopra.
Questo è usato in una chiamata ma non sembra che sia usato dal codice di decodifica. Il motivo è che VirtualProtect arrotonda l’area di memoria su cui lavora alla dimensione di una pagina (4KiB), per cui anche gli indirizzi precedenti a theAddress possono venir modificati.
Utilizzando un breakpoint hardware è possibile ricostruire le chiamate effettuate e risalire al codice chiamante presente in Rebone.
Alternativamente è possibile vedere che poco prima di theAddress, un altro indirizzo viene referenziato (che abbiamo chiamato theHeader).
Leggendo il codice che usa theHeader e le chiamate che effettua, è possibile ricostruire il flusso di decodifica.
Questo utilizza un semplice algoritmo di decodifica per ottenere il codice di unpacking e poi utilizza un salto indiretto per eseguirlo.
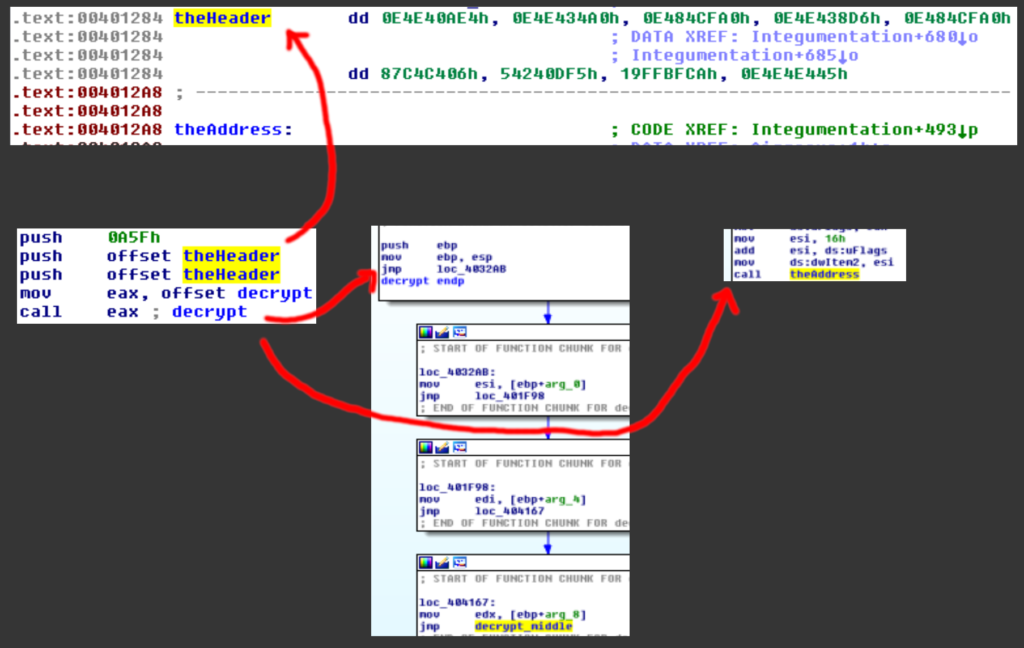
c = 9 x = x + 0x1a x = ror(x, 4) x = x ^ c x = ror(x, 4) x = x - c x = ror(x, 1) x = x + 0x11 x = ror(x, 2) x = x ^ 0x53 x = ror(x, 1) x = x + 0x1a x = ror(x, 3) x = x + 0x19 x = x ^ 0x53
Una volta eseguito l’algoritmo di decodifica, Ursnif chiama il codice a theAddress ma prima di vedere il codice del packer è utile dare un’occhiata ai dati decodificati.
Per gran parte trattasi di codice ma una piccola parte (quella prima di theAddress) sono dei metadati.
E’ inoltre utile osservare come questo BLOB di dati si trovi nella directory di export della DLL, più precisamente tra l’header e la prima stringa (in ordine di offset) o tabella usata in quest’ultimo.
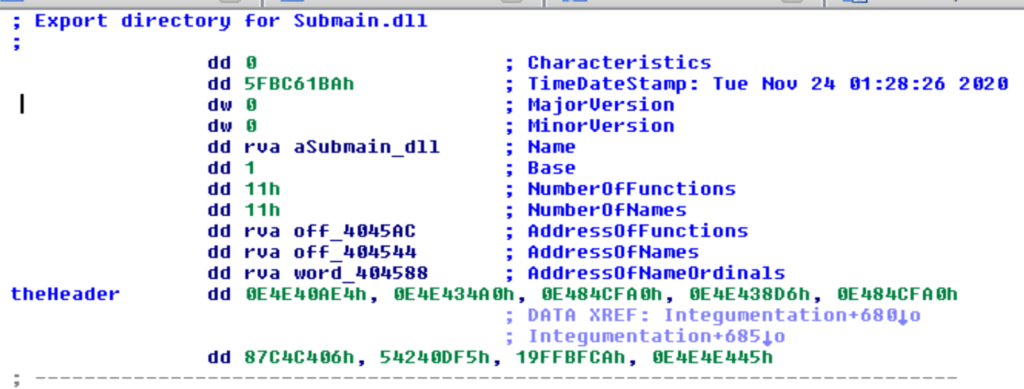
L’header decodificato ha la seguente forma:
00181284 00 AE 00 00 A1 9B 00 00 A1 38 01 00 10 7B 00 00 .®..¡...¡8...{..
00181294 A1 38 01 00 8E 07 07 92 9D 46 1E 94 F0 BE AC 66 ¡8.......F..ð¾¬f
001812A4 03 00 00 00
Di questo header i campi rilevanti sono:
- La quarta DWORD è l’RVA del payload codificato. I dati sono in formato “chunked” (descritto sotto).
- La terza DWORD è la dimensione del payload codificato.
- La sesta DWORD è il CRC32 del payload codificato.
- La seconda DWORD è la dimensione del payload decodificato.
- La settima DWORD è il CRC32 del payload decodificato.
Il codice di unpacking
Il codice di unpacking è molto semplice da analizzare. Può essere riassunto come segue.
- Usa il PEB per ottenere
ZwAllocateVirtualMemorye alloca un’area di memoria eseguibile dove copierà la seconda parte del proprio codice. - Chiama
LoadLibraryAeGetProcAddresscon valori non validi. Se tuttavia ottiene un puntatore ad una funzione valido, entra in un ciclo infinito. Ripete per 0x640 volte.
E’ un modo di perdere tempo e, se apportunamente configurato, verificare la presenza di sandbox. - Continua l’esecuzione dal buffer allocato dove avervi copiato parte del proprio codice.
- Recupera
NtProtectVirtualMemorye alloca due buffer (uno è di lavoro, uno è per il payload finale). - I dati del payload sono divisi in chunk (il primo indicato dall’header).
Ogni chunk inizia con due DWORD che indicano rispettivamente l’RVA del prossimo e la dimensione del chunk corrente.
Il codice legge ogni chunk e lo scrive nel buffer di lavoro. - Il payload è stato codificato inserendo dei byte inutili casualmente. Utilizzando lo stesso seed e lo stesso RNG, il packer li rimuove e ottiene il payload quasi nella sua forma finale.
Di seguito lo pseudo codice.
seed = 0x7eb2;
src = buffer;
dst = buffer;
size = ...;
while (size > 0)
{
int len = rng(&seed);
memcpy(dst, src+2, len);
dst += len;
size -= (len + 2);
}
- Infine il payload è decodificato con un algoritmo custom che utilizza semplici operazioni logico aritmetiche sui singoli byte.
UUE – Universal Ursnif Extractor
Gli algoritmi di decodifica del payload sono variati da sample a sample e nel corso della storia di Ursnif lo stesso packer è variato quanto basta per rendere l’estrazione automatica sempre più problematica.
Un’approccio statico è quindi difficile da finalizzare, è meglio concentrarsi su uno dinamico.
L’idea è quella di modificare le funzione NtAllocateVirtualMemory e NtProtectVirtualMemory in modo che queste rimuovano silenziosamente l’attributo X (eseguibile) dai permessi di memoria.
Così facendo i buffer allocati da Ursnif non saranno eseguibili. Inoltre i vari buffer allocati (inizio e dimensione) sono salvati in un insieme B.
Con un exception handler sono controllati i page fault che cadono in un buffer in B e, in caso di esito positivo, si ripristinano i permessi di esecuzione.
Prima di ritornare dall’exception handler viene controllata la presenza di un payload PE nei buffer in B e, se trovato, questo viene salvato su file e il processo interrotto.
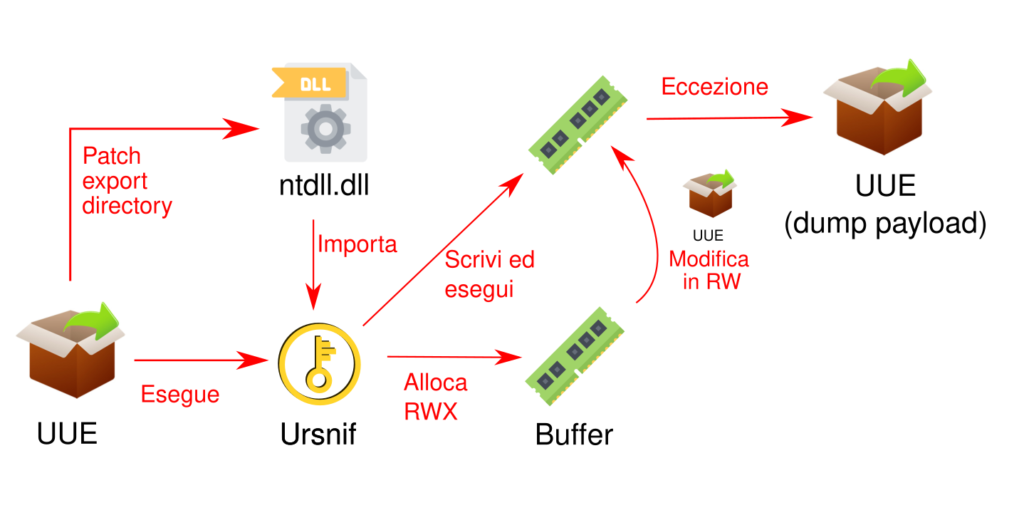
La versione attuale di UUE supporta solo loader in DLL ma è possibile aggiungere il supporto per gli eseguibili (si tratta di isolare il codice in una DLL iniettabile nel processo del packer).
Inoltre la linea di azione corretta vorrebbe che si mantenesse l’invariante W^X per le aree di memoria, ovvero quando per un buffer viene ripristinato il permesso di esecuzione andrebbe rimosso il permesso di scrittura, in modo da catturare eventuali modifiche.
Al momento questo non è necessario.
Gli hook alle API sono installati modificando la directory di esportazione di ntdll.dll, il base address di questa dll è ottenuto tramite il PEB, come fa Ursnif.
Dato che le importazioni di un PE sono effettuate dal loader al momento del lancio, le modifiche all’export directory di ntdll non impattano le API di UUE importate staticamente (in pratica, UUE non installa hook sulle proprie API).
UUE è un eseguibile Windows che si aspetta da linea di comanda la DLL del packer.
Data la natura dinamica dell’estrazione, è sempre necessario eseguirlo in una VM di analisi.
>uue.exe 5fbcff906d6ec.dll
[Dumped!]
>dir
5fbcff906d6ec.dll ...
5fbcff906d6ec.payload0.dll ...Sample meno recenti
I sample di Ursnif del secondo quadrimestre del 2020 seguivano lo stesso flusso di lavoro dei sample recenti.
Anche per questi UUE dovrebbe essere in grado di estrarre il payload (ma non lo abbiamo testato).
A differire con i sample recenti sono i dettagli implementativi.
E’ sempre presente una gran quantità di codice superfluo che presenta rami di esecuzione impossibili e chiamate API inutili.
Un altro pattern presente nel codice offuscato del packer è quello che prende la forma di un ciclo con un gran numero di iterazioni.
All’interno del ciclo vi sono rami di codice che sono eseguiti solo a partire da una data iterazione in poi.
Il tutto sempre contornato di codice non raggiungibile e chiamate API inutili.
Tutto questo ha lo scopo di confondere l’analista e di ritardare l’esecuzione del codice malevolo.
Anche questi sample di metà 2020 decifrano il codice di unpacking, ma anzichè farlo in-place come i sample recenti, allocano un buffer con GlobalAlloc (che è un’ottima API dove piazzare un breakpoint). Quest’API è recuperata con GetProcAddress e GetModuleHandleW, sia quest’ultime API chè le stringhe usate sono in chiaro.
Una volta allocato il buffer, il codice di unpacking viene copiato e decifrato nel buffer allocato.
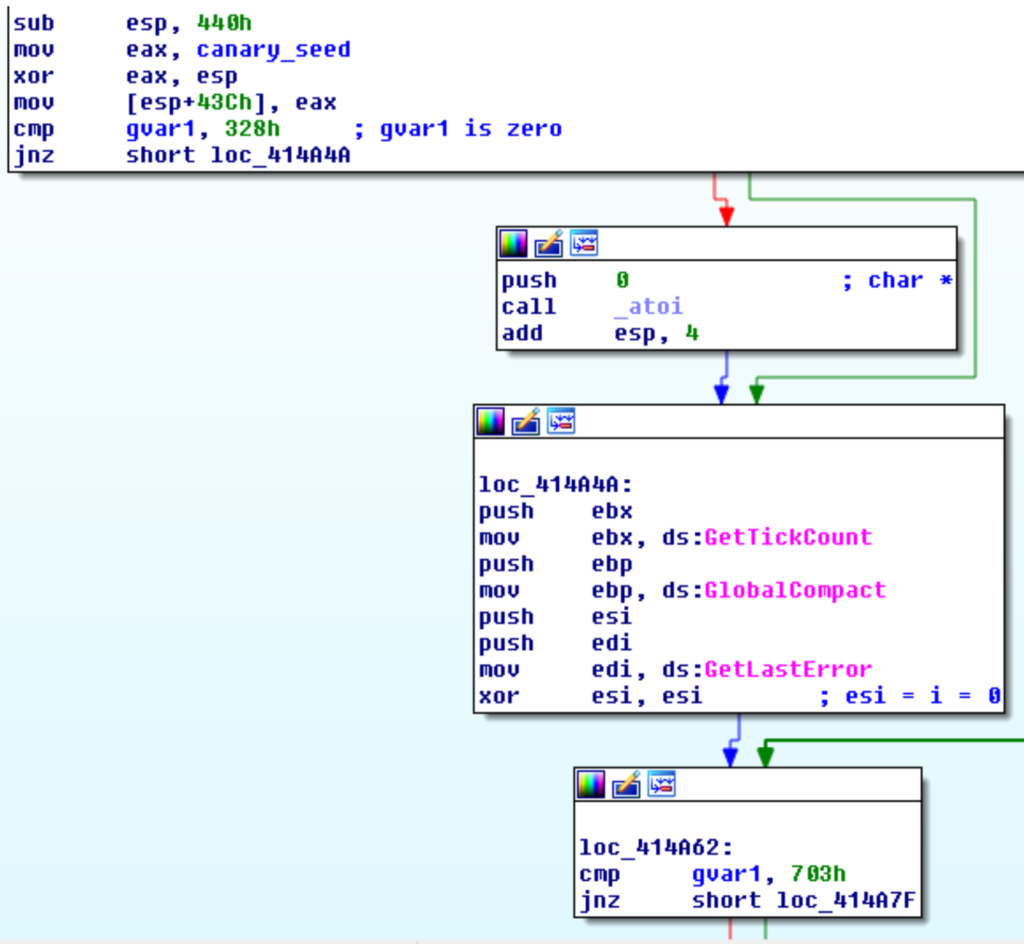
La dimensione e la posizione del codice di unpacking è determinata tramite l’uso di due variabili globali ed una costante fissa.
encrypted_code_size = gvar2 + K;
encrypted_code_ptr = gvar3 + K;Sia la costante che la posizione delle variabili globali cambiano di sample in sample e non sono facili da recuperare in modo automatico.
Il codice di unpacking è decifrato in alcuni sample con RC4 PRGA ed in altri con TEA (Tiny Encryption Algorithm), ma non possiamo escludere l’utilizzo di altri algoritmi ancora.
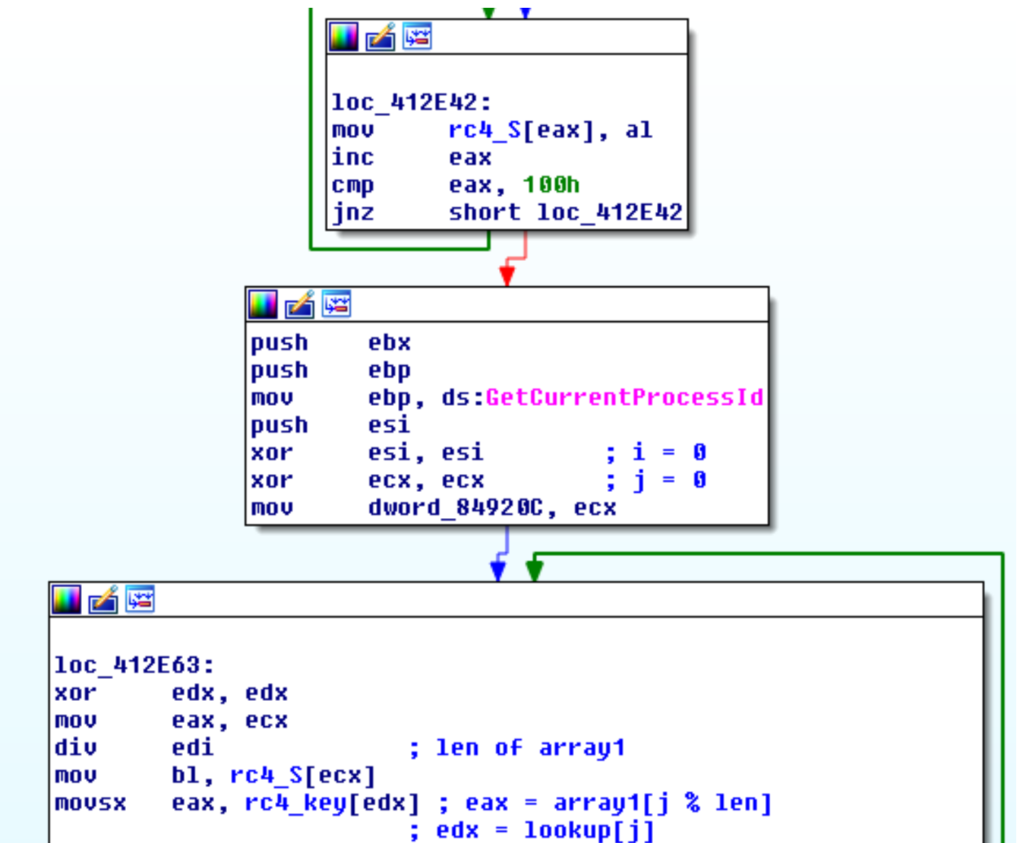

Una volta decifrato il codice di unpacking, il packer lo rende eseguibile con VirtualProtect e lo esegue usando un salto indiretto.
Questa è una costante di tutte le varianti: alla fine verrà sempre usato un salto indiretto per eseguire il codice di unpacking.
Campioni di Ursnif ancora più vecchi (seconda metà del 2018) seguono ancora una volta il copione sopra descritto, ma ancora una volta i dettagli sono diversi.
In quei sample, il codice di unpacking è prima copiato in un’area apposita nella sezione dei dati (quindi scrivibile), decodificato e poi reso eseguibile con VirtualProtect.
Non è facile individuare il codice responsabile della decodifica, in generale si tratta di algoritmi semplici (tipo sommare una costante ad ogni DWORD del codice di unpacking) ma questi variano da sample a sample.
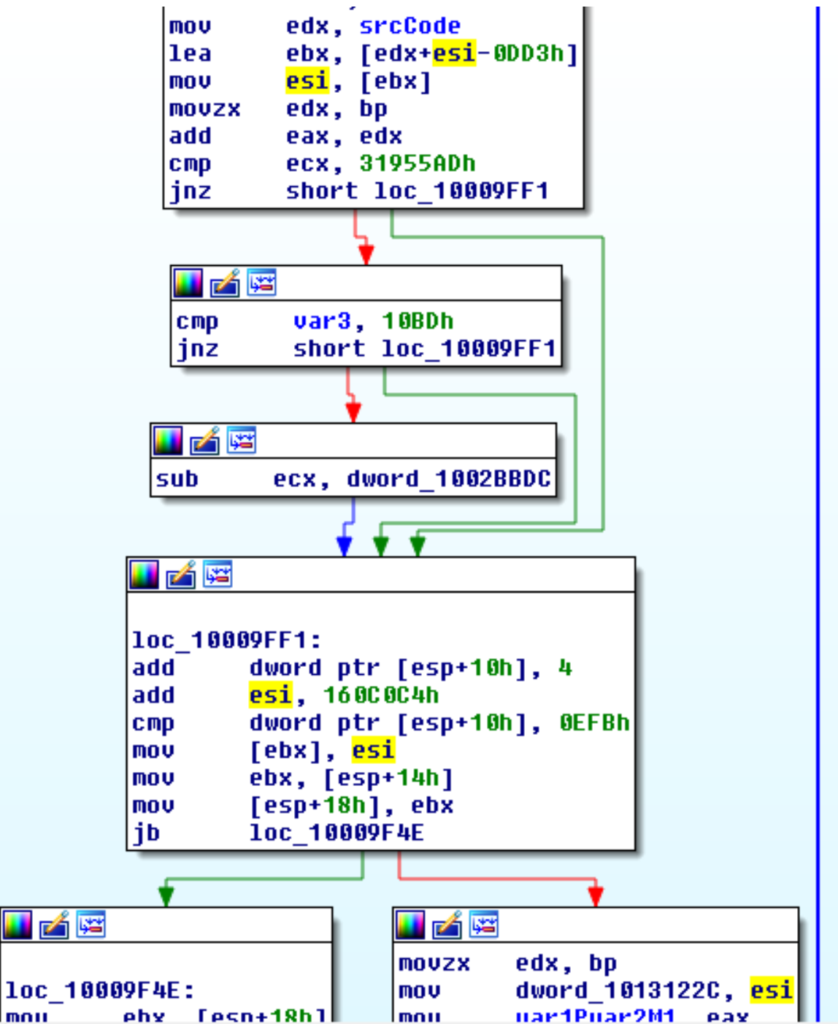
Ancora una volta il codice di unpacking è eseguito tramite un salto indiretto. In questi vecchi sample il compito era affidato ad una coppia di istruzioni push/ret.
Il codice di unpacking non presenta grosse difficoltà per l’analista.
I sample del 2020 e quelli del 2018/19 presentano codici diversi, anche se i passi eseguiti sono sempre gli stessi: viene recuperato il payload, questo viene decodificato, decompresso (se necessario) ed infine mappato ed eseguito.
Le API necessarie sono importate tramite il PEB e usando una funzione di hash per individuare l’API esatta da importare (un trucco ben noto).
Per ottenre il proprio base address il packer può usare CreateToolhelp32Snapshot e Module32First anzichè GetModuleHandle.
La decodifica del payload utilizza tecniche che sono variate nel tempo. Una di queste consisteva nell’inizializzare un RNG (rand nello specifico) con un seed specifico e nell’utilizzare la sequenza di numeri ottenuti come chiave XOR per il payload.
Simili algoritmi sono stati visti in sample più vecchi, un RNG minimale era usato per ottenere il prossimo valore da usare per lo xor.
La decompressione del payload è opzionale e nei campioni di metà 2020 utilizava un algoritmo che non abbiamo riconosciuto.
I sample più vecchi utilizzavano invece aPLib.
Consigli per il reverse engineering
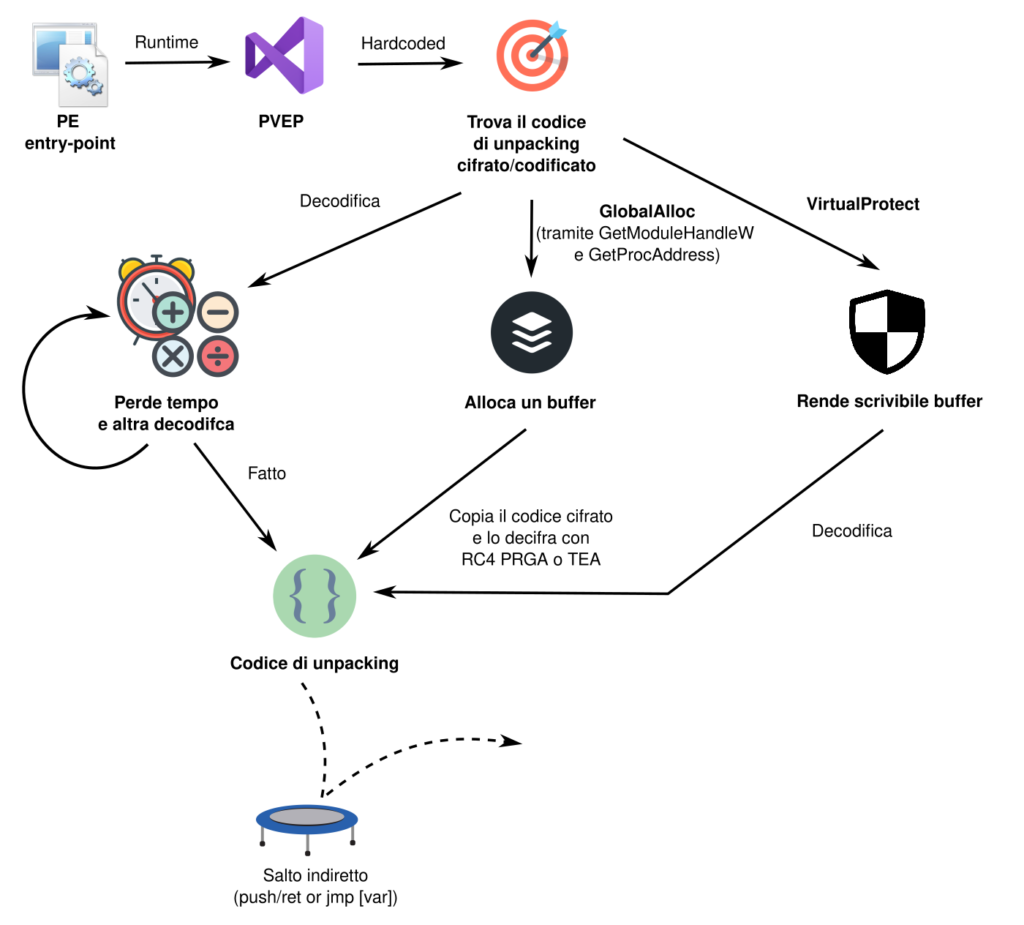
L’attenzione dell’analista dovrebbe porsi sulle allocazioni di memoria e sui salti indiretti.
Istruzioni come jmp reg32, call reg32 o push/ret indicano quasi sempre dove si trova il vero codice malevolo del packer.
Tuttavia non è facile individuarle nel mare di istruzioni inutili, un altro approccio è quello di mettere un breakpoint sulle funzioni di allocazione o protezione della memoria.
VirtualProtect, nello specifico, è sempre stata usata fin ora. Ovviamente è possibile che il malware passi all’uso delle funzioni equivalenti in ntdll, per cui è fare una ricognizione del codice prima di mettere breakpoint.
L’accesso al TEB o API come GetProcAddress sono altri possibili luoghi dove piazzare breakpoint.
Il lavoro più difficile è individuare quando viene eseguito il codice di unpacking, quest’ultimo è semplice da seguire.
Di seguito un resoconto del flusso di lavoro del packer per eseguire il codice di unpacking.
Nel prossimo articolo analizzeremo il payload estratto dal packer. Questo risulterà essere a sua volta un altro packer ma contiene delle tecniche usate anche dagli stadi successivi e che è fondamentale comprendere ed analizzare per lo sviluppo di strumenti automatici.